Stay Confident
Subscribe to our weekly newsletter to stay confident in the AI systems you build.

Introducing Report Templates: Build the report your team actually reads
Report Templates let you customize the reports Confident AI generates for your team. Build daily reports that dig into traces, identify where your AI agent is underperforming, summarize common usage patterns, and show the exact pages and sections you care about.

Jeffrey Ip

AI Agent Observability: Everything You Need to Know in 2026
Everything you need to know about AI agent observability in 2026 — traces, spans, and threads; online and offline evals; production monitoring; and closing the feedback loop so failures never repeat.

Kritin Vongthongsri

Introducing Synthetic Data Generation Pipelines: Customize how you generate data
Many teams already had great synthetic data generation pipelines running locally, but consolidating that work on one platform usually meant giving up flexibility. Synthetic Data Generation Pipelines bring that control into Confident AI: choose the sources to draw context from, wire them together, and tune each generation step.
Jeffrey Ip

Introducing Annotation Forms: Capture any human feedback without leaving Confident AI
Human review only helps if everyone captures the same thing. Annotation Forms let you define the exact set of fields reviewers fill in — text, numbers, scales, yes/no, single and multiple choice, and scored criteria — so every annotation comes back structured, consistent, and ready to act on.
Jeffrey Ip

Introducing AI Observability Workflows: Custom automations for every trace on the platform
Dataset ingestion, queue ingestion, evaluation rules, and classifiers have lived on Confident AI for a while — but in separate corners of the product. Workflows brings them into one interface: a single graph of your post-ingestion pipeline, with a tab to configure each task. Here's how it works.
Jeffrey Ip
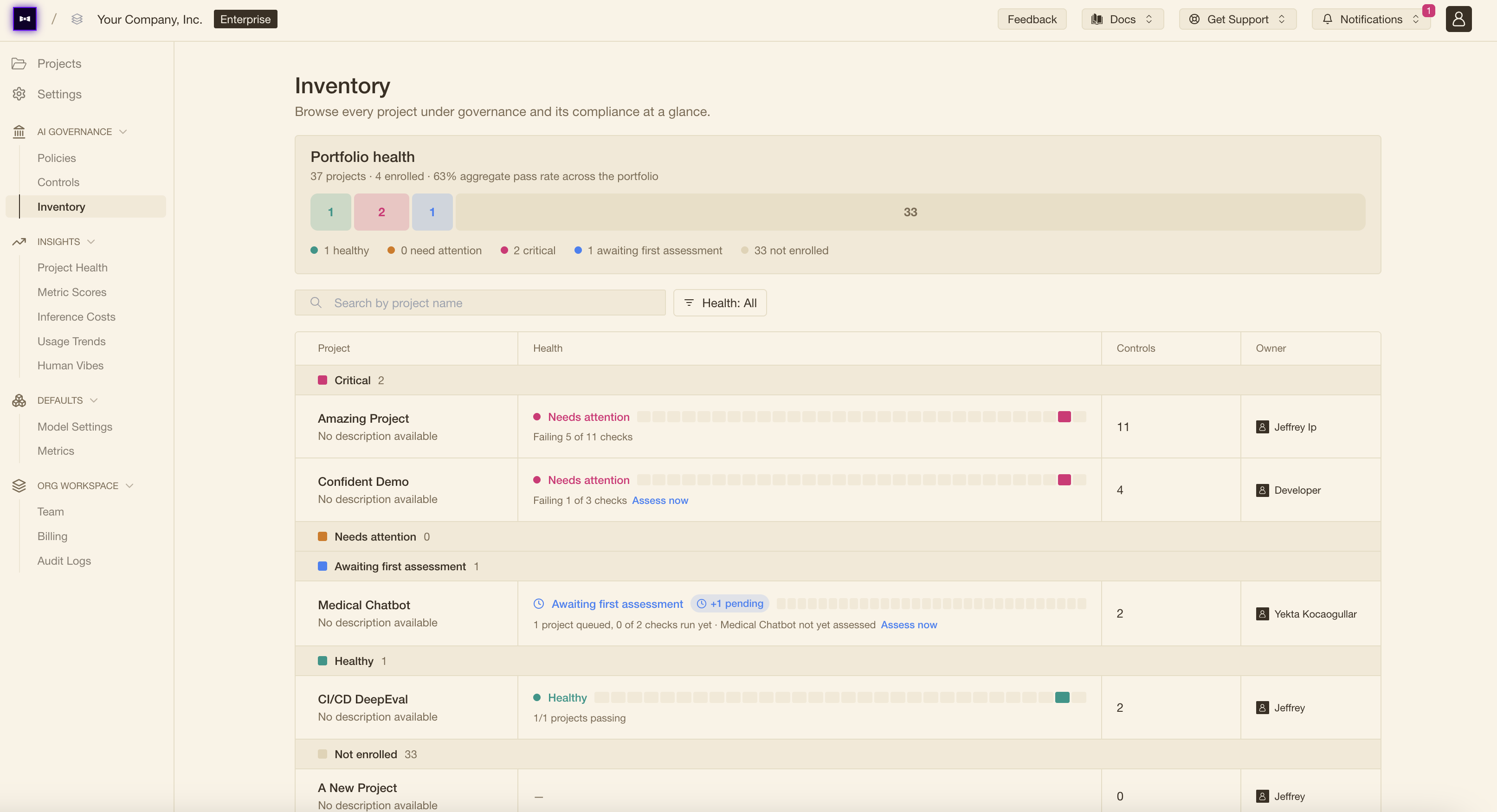
Introducing AI Governance: Standardized evals, policies, and controls
As AI spreads across an org, every team evaluates differently and no one can answer 'is this ready to ship?'. AI Governance is the layer on top of the evals, observability, and red teaming your teams already run — turning those signals into one standard, enforced at deploy time.
Jeffrey Ip

Human-in-the-Loop Workflows for AI Agent Evaluation: Complete Guide
A practical guide to human-in-the-loop workflows for AI agent evaluation: how SMEs review AI agent failures, align automated metrics, and improve evaluation datasets.
Kritin Vongthongsri

LLM Product Manager Workflows: A Complete Guide to AI Quality
A practical guide to LLM product manager workflows, built around the two things PMs can finally do without waiting on engineering: build on the AI product by editing prompts, running evals, and comparing variants, and monitor quality with dashboards, signals, and shareable evidence.
Kritin Vongthongsri

The Complete Guide to LLM Experimentation: Compare Prompts, Models, and Agents
A practical guide to running LLM experiments across prompts, models, tools, datasets, metrics, production A/B tests, and human-in-the-loop feedback loops.
Kritin Vongthongsri

LLM Evaluation for Startups: The Complete Guide
A practical LLM evaluation guide for startups: build a small dataset, use the 2 + 3 metric rule, run CI/CD evals, and grow coverage from production signals and human review.