

Let’s cut to the chase. There are tons of LLM evaluation tools out there, and they all look, feel, and sound the same. “Ship your LLM with confidence, “No more guesswork for LLMs”, ye right.
Why is this happening? Well, turns out LLM evaluation is a problem faced by anyone and everyone building LLM applications, and it sure is a painful one. LLM practitioners rely on “vibe checks”, “intuition”, “gut feel”, and resort to “making up test results to keep my manager happy”.
As a result, there are more than enough high quality LLM evaluation solutions out there in the market, and as the author of DeepEval ⭐, the open-source LLM evaluation framework with almost half a million monthly downloads, it is my duty to let you know the people's choice of top LLM evaluation tools based on their pros and cons.
But before we begin with our top 5 list though, let’s go over the basics.
Why Should You Take LLM Evaluation Seriously?
Here's a common scenario you will be or are already running into: You've built an LLM application that automates X% of some existing tedious, manual workflow either for yourself or a customer, only to later find out that it doesn't perform as well as you'd hoped. Disappointing, you think to yourself, now what do I do? There're only two possible explanations for why your LLM application isn't living up to your expectations - after all, you saw someone else built something similar and it seems to be working fine. Your LLM application either:
Is never going to be able to do the thing you thought it could do
Has the potential to be better
I'm here today to teach you the optimal LLM evaluation workflow to maximize the potential of your LLM application.
The Perfect LLM Evaluation Tool
LLM evaluation is the process of benchmarking LLM applications to allow for comparison, iteration, and improvement. And so, the perfect LLM evaluation tool will enable this process most efficiently and will allow you to maximize the performance of your LLM system.
The perfect LLM evaluation tools must:
Have accurate and reliable LLM evaluation metrics. Without this, you might as well go home and take a nap. Not just metrics that claim to be accurate but hidden behind API walls - you'll want verifiable and battle-tested metrics that are used and loved by many.
Have a way for you to quickly identify improvements and regressions. After all, how are you going to know if you’re iterating towards the right direction otherwise?
Have the capability to curate and manage evaluation datasets, which are datasets used to test your LLM application, in one centralized place. This especially applies to LLM practitioners that rely on domain experts to label evaluation datasets because without this, you will have a poor feedback loop and your evaluation data will suffer.
Be able to help you identify the quality of LLM responses generated in production. This is vital because you’ll want to a) monitor how well different models and prompts are performing in a real-world setting, and b) be able to add unsatisfactory LLM outputs to your dataset to improve your testing data over time.
Be able to include human feedback to improve the system. This may be feedback from your end user, or even feedback from your team.
Remember, great LLM evaluation == Quality of metrics x Quality of dataset, so prioritize this above all else. That being said, let’s talk about the top 5 tools that does this best.
1. Confident AI
Confident AI takes top spot for a simple reason: it is powered by the best LLM evaluation metrics available, and has the most streamlined workflow for curating and improving the quality of evaluation datasets over time. It provides the necessary infrastructure to identify what your LLM application needs to improve on, as well as catching regressions pre-deployment, making it the leading LLM evaluation solution out there.
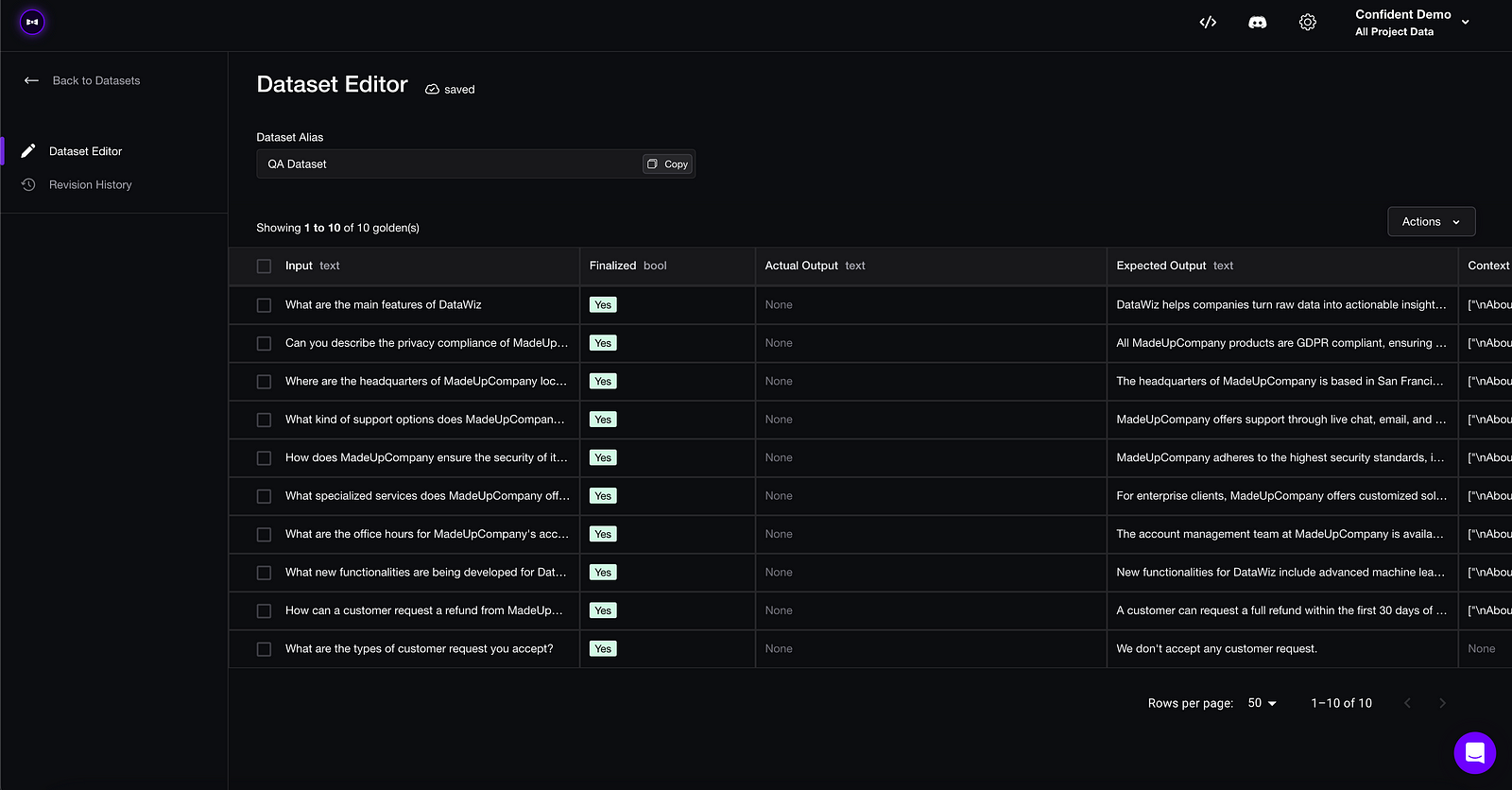
Unlike its counterparts, its metrics are powered by DeepEval, which is open-source and has ran over 20 million evaluations with over 400k monthly downloads, and covers everything from RAG, agents, and conversations. Here’s how it works:
Upload an evaluation dataset with a set of ~10–100 inputs and expected output pairs, which non-technical domain experts can annotate and edit on the platform.
Choose your metrics (covers all use cases).
Pull the dataset from the cloud, and generate LLM outputs for your dataset.
Evaluate.
Each time you make an update to your prompt, model, or anything else, simply rerun the evaluation to benchmark your updated LLM system. Here’s how it looks like:
pip install deepevalfrom deepeval import evaluate
from deepeval.metrics import AnswerRelevancy
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset()
# supply your alias
dataset.pull(alias="My Dataset")
# testing reports will be on Confident AI automatically
evaluate(dataset, metrics=[AnswerRelevancy()])If you don’t have an evaluation dataset to start with, simply:
Choose your metrics and turn them on for LLM monitoring
Start monitoring/tracing LLM responses in production
Filter for unsatisfactory LLM responses based on metric scores, and create a dataset out of it.
The best part? It has a stellar developer experience (trust me, I got a lot of harsh feedback in the early days improving the developer flow), and is free to use right away. Give it a try yourself, it will only take 20 minutes of your time: https://app.confident-ai.com
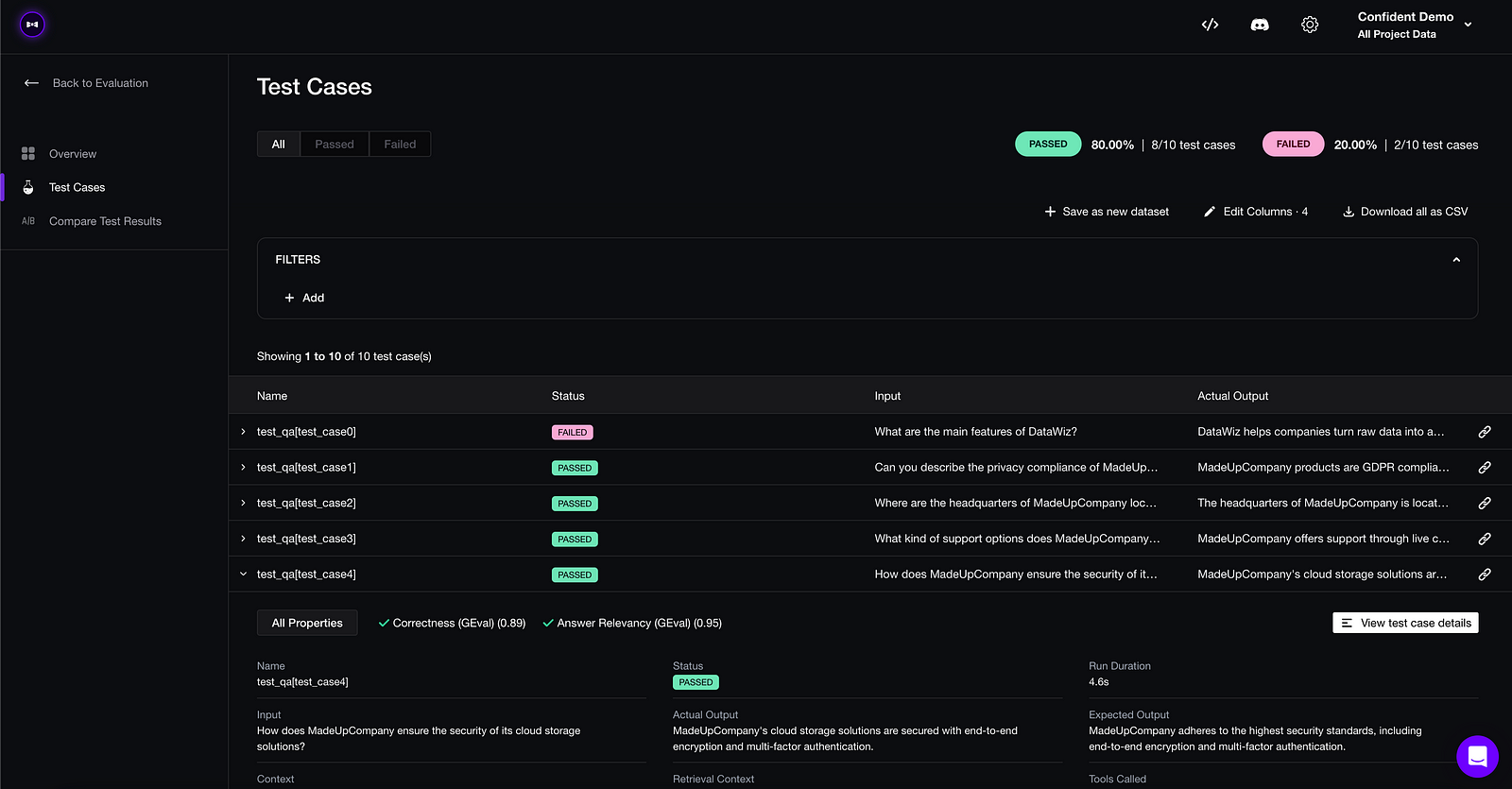
2. Arize AI
Arize AI delivers powerful, real-time monitoring and troubleshooting for LLMs, making it an essential tool for identifying performance degradation, data drift, and model biases. Alike Confident AI, it offers great tracing capabilities for easy debugging, but it does not have the level of support for evaluation datasets you’d want, making it 2nd on the list. Remember, great LLM evaluation == Quality of metrics x Quality of dataset.
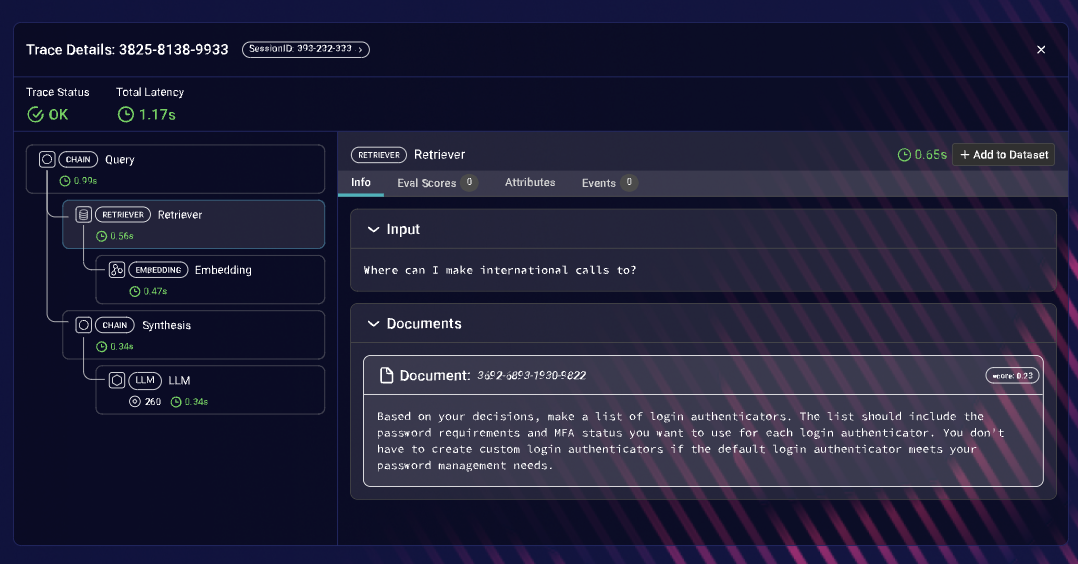
However, one standout feature is its ability to provide granular analysis of model performance across segments. It pinpoints specific domains where the model falters, such as particular dialects or unique circumstances in language processing tasks. For fine-tuning models to achieve consistently high performance across all inputs and user interactions, this segmented analysis is indispensable.
Confident AI: The DeepEval LLM Evaluation Platform
The leading platform to evaluate and test LLM applications on the cloud, native to DeepEval.



