

Here’s the strange thing about LLM evaluation in 2026: an LLM judge agrees with human reviewers about 85% of the time — higher than two humans agree with each other on the same task. That’s the bet behind LLM-as-a-Judge, now the default method for evaluating LLM applications at scale.
The idea is simple. Have one LLM score the outputs of another against criteria you define — answer relevancy, faithfulness, helpfulness, bias, correctness. No annotation team, no waiting weeks, no five-figure human eval contract. Just a prompt and an API call.
But LLM judges aren’t plug-and-play. The wrong scoring method, the wrong prompt, the wrong rubric, and your eval scores end up just as flaky as the model you’re testing.
This guide is the complete playbook on LLM-as-a-Judge — what it is, single-output vs pairwise scoring, the techniques that make judges accurate (G-Eval, DAG, chain-of-thought, few-shot prompting), how to handle bias and other limitations, and how to wire it all into production evaluation metrics with DeepEval.
Let's begin.
Tl;DR
- LLM-as-a-Judge is the most scalable, accurate, and reliable way to evaluate LLM apps when compared to human annotation and traditional scores like BLEU and ROUGE (backed by research)
- There are two types of LLM-as-a-Judge, "single output" and "pairwise".
- Single output LLM-as-a-Judge scores individual LLM outputs by outputting a score based on a custom criterion. They can be referenceless, or reference-based (requires a labelled output), and G-Eval is current one of the most common ways to create custom judges.
- Pairwise LLM-as-a-judge on the other hand does not output any score, but instead choose a "winner" out of a list of different LLM outputs for a given input, much like the automated version of LLM arena.
- Techniques to improve LLM judges include CoT prompting, in-context learning, swapping positions (for pairwise judges), and much more.
- DeepEval (100% OS ⭐https://github.com/confident-ai/deepeval) allows anyone to implement both single output and pairwise LLM-as-a-Judge in under 5 lines of code, via G-Eval and Arena G-Eval respectively.
What is LLM-as-a-Judge?
LLM-as-a-Judge is an LLM evaluation method that uses a large language model to automatically score the outputs of another LLM system against a defined criterion. It works by feeding an evaluation prompt — containing the criterion, the input, and the generated output — to a judge LLM, which returns a numeric score, a binary verdict, or a preference between two outputs.
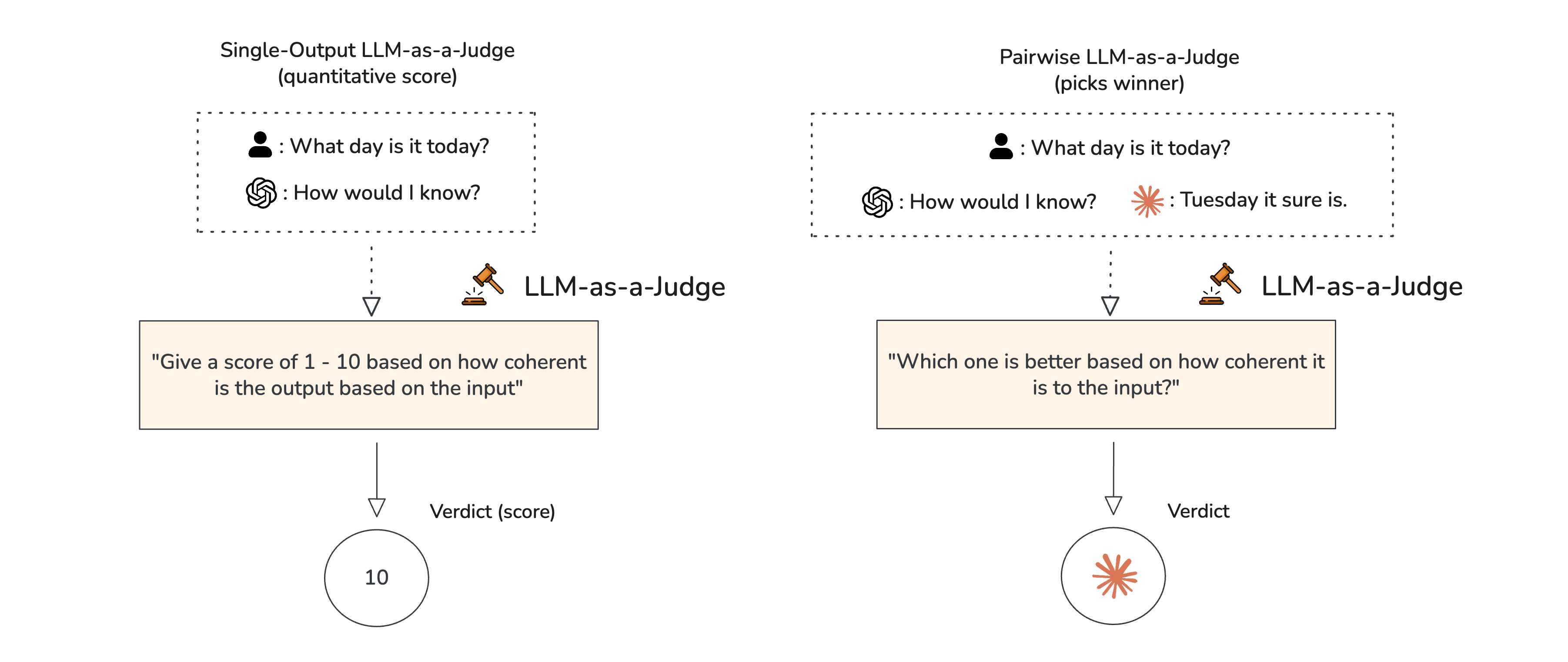
Types of LLM-as-a-Judges
There are many types of LLM-as-a-judges for different use cases:
- Single-output: Either reference-based or referenceless, takes in a single or multi-turn LLM interaction and outputs a quantitative verdict based on the evaluation prompt.
- Pairwise: Similar to LLM arena, takes in a single or multi-turn LLM interaction and outputs which LLM app gave the better output.
We'll go through all of these in a later section, so don't worry about these too much right now.
In the real world, LLM judges are often time used as scorers for LLM-powered evaluation metrics such as G-Eval, answer relevancy, faithfulness, bias, and more. These metrics are then often times used to evaluate different LLM systems such AI agents. The concept is straightforward: provide an LLM with an evaluation criterion, and let it do the grading for you.
But how and where exactly would you use LLMs to judge LLM responses?
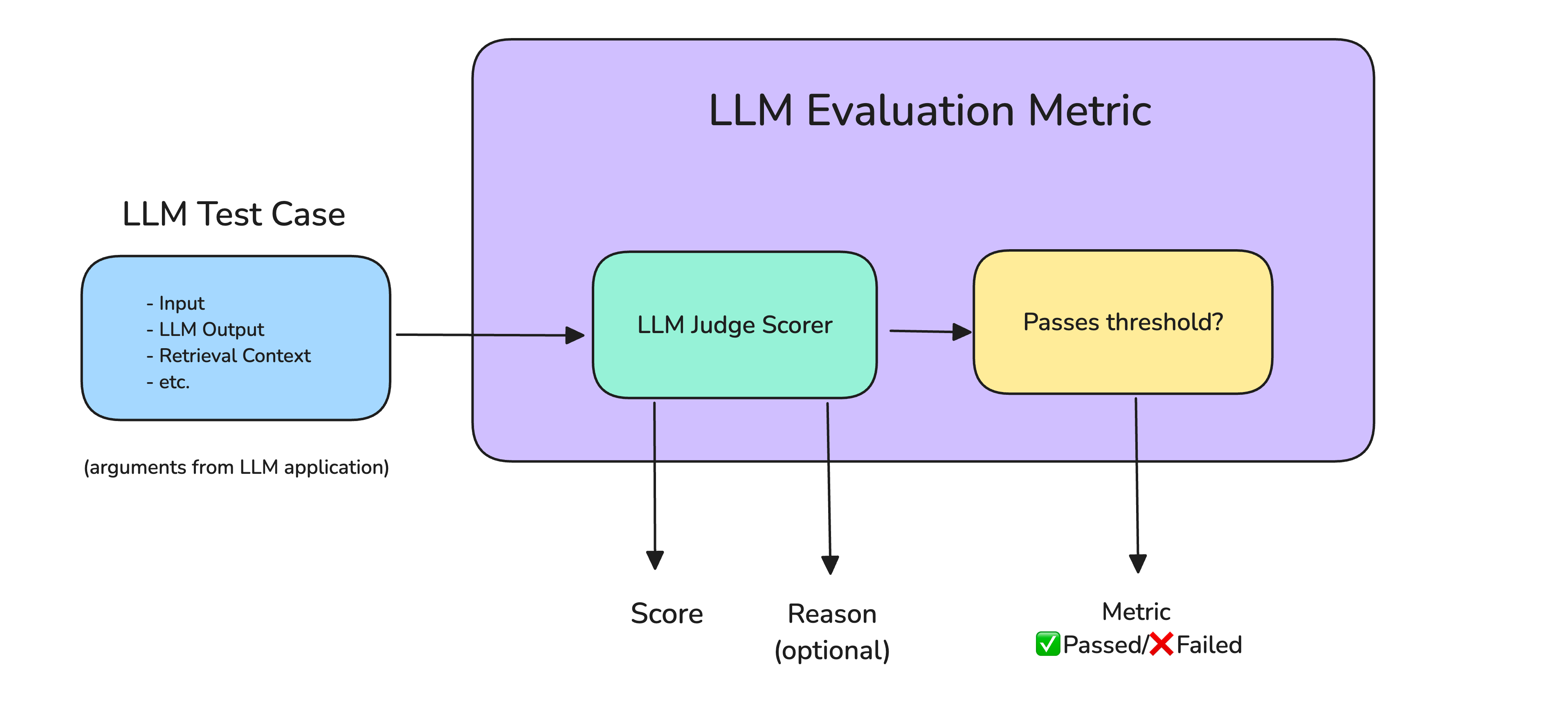
*Using LLM Judges as Scorers in Metrics *
LLM-as-a-judge can be used as an automated grader/scorer for your chosen evaluation metric. To get started:
- Choose the LLM you want to act as the judge.
- Give it a clear, concise evaluation criterion or scoring rubric.
- Provide the necessary inputs - usually the original prompt, the generated output, and any other context it needs.
The judge will then return a metric score (often between 0 and 1) based on your chosen parameters. For example, here’s a prompt you could give an LLM judge to evaluate summary coherence:
prompt = """
You will be given one summary (LLM output) written for a news article.
Your task is to rate the summary on how coherent it is to the original text (input).
Original Text:
{input}
Summary:
{llm_output}
Score:
"""By collecting these metric scores, you can build a comprehensive set of LLM evaluation results to benchmark, monitor, and regression-test your system. LLM-as-a-Judge is gaining popularity because the alternatives fall short — human evaluation is slow and costly, while traditional metrics like BERT or ROUGE miss deeper semantics in generated text.
It makes sense: How could we expect traditional, much smaller NLP models to effectively judge not just paragraphs of open-ended generated text, but also content in formats like Markdown or JSON?
LLM-as-a-Judge Use Cases
Before we go any further, it is important to understand that LLM-as-a-Judge can be used to evaluate both single and multi-turn use cases.
Single-turn refers to a single, atomic, granular interaction with your LLM app. Multi-turn on the other hand, is mainly for conversational use cases and contains not one but multiple LLM interactions. For example, RAG QA is a single-turn use case since no conversation history is involved, while a customer support chatbot is a multi-turn one.
LLM judges that score single-turn use cases expects the input and output of the LLM system you're trying to evaluate:

Single-Turn LLM-as-a-Judge
On the other hand, using LLM judges for multi-turn use cases involves feeding in the entire conversation into the evaluation prompt:

Multi-Turn LLM-as-a-Judge
Multi-turn use cases are less accurate in general because there is a greater chance of context overload. However, there a various techniques to get over this problem, which you can learn more about in LLM chatbot evaluation here.
One important thing to note is, LLM judge verdicts doesn't have to be a score between 1 - 5, or 1 - 10. The range is flexible, and can also sometimes be binary, which amounts to a simple "yes" or "no" at times:

LLM-as-a-Judge with Binary "yes" or "no" Verdicts
Types of LLM-as-a-Judge
As introduced in the "Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena" paper as an alternative to human evaluation, which is often expensive and time-consuming, the three types of LLM as judges include:
- Single Output Scoring (without reference): Judge LLM scores one output using a rubric, based only on the input and optional "retrieval context" (and tools that were called).
- Single Output Scoring (with reference): Same as above, but with a gold-standard "expected output" to improve consistency.
- Pairwise Comparison: Judge LLM sees two outputs for the same input and picks the better one based on set criteria. They let you easily compare models, prompts, and other configs in your LLM app.
⚠️ Importantly, these three judging approaches are not limited to evaluating single-turn prompts; they can also be applied to multi-turn interactions, especially for a chatbot evaluation use case.
Single-output (referenceless)
This approach uses a reference-less metric, meaning the judge LLM evaluates a single output without being shown an ideal answer. Instead, it scores the output against a predefined rubric that might include factors like accuracy, coherence, completeness, and tone.

Single-Output LLM-as-a-Judge
Typical inputs include:
- The original input to the LLM system
- Optional supporting context, such as retrieved documents in a RAG pipeline
- Optional tools called, nowadays especially for evaluating LLM agents
Example use cases:
- Evaluating the helpfulness of customer support chatbot replies.
- Scoring fluency and readability of creative writing generated by an LLM.
Because no gold-standard answer is provided, the judge must interpret the criteria independently. This is useful for open-ended or creative tasks where there isn’t a single correct answer.
Single-output (reference-based)
This method uses a reference-based metric, where the judge LLM is given an expected output in addition to the generated output. The reference acts as an anchor, helping the judge calibrate its evaluation and return more consistent, reproducible scores. Typical inputs include:
- The original input to the LLM system.
- The generated output to be scored.
- A reference output, representing the expected or optimal answer.
Example use cases resolve around correctness:
- Assessing the answer correctness of LLM-generated math solutions to labelled solution.
- Assessing code correctness against a known correct implementation.
The presence of a reference makes this approach well-suited for tasks with clear “correct” answers. It also helps reduce judgment variability, especially for nuanced criteria like factual correctness.
Pairwise comparison
Pairwise evaluation mirrors the approach used in Chatbot Arena, but here the judge is an LLM instead of a human. The judge is given two candidate outputs for the same input and asked to choose which one better meets the evaluation criteria.

Pairwise LLM-as-a-Judge, taken from the MT-Bench paper.
Typical inputs include:
- The input to the LLM systems
- Two candidate outputs, labeled in random order to prevent bias.
- Evaluation criteria defining “better” (e.g., accuracy, helpfulness, tone).
This method avoids the complexity of absolute scoring, instead relying on relative quality judgments. It is particularly effective for A/B testing models, prompts, or fine-tuning approaches — and it works well even when scoring rubrics are subjective.
Example use cases:
- Determining whether GPT-4 or Claude 3 produces better RAG summaries for the same query.
- Choosing between two candidate marketing email drafts generated from the same brief.
If you stick till the end, I'll also show you what an LLM-Arena-as-a-Judge looks like.
Effectiveness of LLM-as-a-Judge
LLM-as-a-Judge often aligns with human judgments more closely than humans agree with each other. At first, it may seem counterintuitive - why use an LLM to evaluate text from another LLM?
The key is separation of tasks. We use a different prompt - or even a different model - dedicated to evaluation. This activates distinct capabilities and often reduces the task to a simpler classification problem: judging quality, coherence, or correctness. Detecting issues is usually easier than avoiding them in the first place.
Our testing at Confident AI shows LLM-as-a-Judge, whether single-output or pairwise, achieves surprisingly high alignment with human reviewers.

Alignment rate of single (G-Eval) vs pairwise (Arena G-Eval) LLM as a judge over 250k annotated test cases each
Our team aggregated annotated test cases from customers (in the form of thumbs up, thumbs down) over the past month, split the data in half, and calculated the differences in agreement between humans, and regular/arena based LLM-as-a-judge separately (implemented via G-Eval, more on this later).
LLM-as-a-Judge vs human evaluation vs traditional NLP metrics
While this section arguably shouldn’t exist, two commonly preferred - but often flawed - alternatives to LLM-based evaluation are worth addressing. Here's how the three approaches stack up:
LLM-as-a-Judge | Human evaluation | Traditional NLP metrics (BLEU, ROUGE, BERTScore) | |
|---|---|---|---|
Scales to 100k+ outputs | Yes | No (~52 days/month for 100k) | Yes |
Cost per evaluation | Low (cents) | High ($1–5+/example) | Near zero |
Latency | Seconds | Hours to days | Milliseconds |
Handles open-ended outputs | Yes | Yes | Poor (needs reference text) |
Captures semantic nuance | Yes | Yes | No |
Explainable (returns reasoning) | Yes | Yes | No |
Consistency / reproducibility | Medium (~85% with GPT-4) | Low (~81% inter-annotator) | High |
Requires reference output | Optional | Optional | Required |
Aligns with human judgement | ~85% (GPT-4) | Baseline | <60% on open-ended tasks |
- Human evaluation — Often considered the "gold standard" for its ability to capture context and nuance, but it's slow, costly, inconsistent, and impractical at scale.
- Traditional NLP metrics (e.g., BERT, ROUGE) — Fast and cheap, but require a reference text and miss semantic nuances in open-ended, complex outputs.
Both human and traditional NLP evaluation methods also lack explainability, which is the ability to explain the evaluation score it has given. With that in mind, let’s go through the effectiveness of LLM judges and their pros and cons in LLM evaluation.
AI Quality for the entire organization, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.
Top LLM-as-a-Judge Scoring Methods
So the question is, how accurate are LLM judges? After all, LLMs are probabilistic models, and are still susceptible to hallucination, right?
Research has shown that when used correctly, state-of-the-art LLMs such as GPT-4 (yes, still GPT-4) have the ability to align with human judgement to up to 85%, for both pairwise and single-output scoring. For those who are still skeptical, this number is actually even higher than the agreement among humans (81%).
There are also many techniques to improve LLM-as-a-judge accuracy, like CoT prompting and few-shot learning, which we'll talk more about later. We've also found success in confining LLM-judge outputs to extremes, making metric scores highly deterministic. In DeepEval, we've enabled users to construct decision trees—modeled as DAGs where nodes are LLM judges and edges represent decisions—to create highly deterministic evaluation metrics that precisely fit their criteria. You'll be able to read about this more in the "DAG" section.
G-Eval
As introduced in one of my previous articles, G-Eval is a framework that uses CoT prompting to stabilize and make LLM judges more reliable and accurate in terms of metric score computation (scroll down to learn more about CoT).

G-Eval algorithm
G-Eval (docs here) first generates a series of evaluation steps using from the original evaluation criteria and uses the generated steps to determine the final score via a form-filling paradigm (this is just a fancy way of saying G-Eval requires several pieces of information to work). For example, evaluating LLM output coherence using G-Eval involves constructing a prompt that contains the criteria and text to be evaluated to generate evaluation steps, before using an LLM to output a score from 1 to 5 based on these steps.
As you’ll learn later, the technique presented in G-Eval actually aligns with various techniques we can use to improve LLM judgements. You can use G-Eval immediately in a few lines of code through DeepEval⭐, the open-source LLM evaluation framework.``
pip install deepevalfrom deepeval.test_case import LLMTestCase, LLMTestCaseParams
from deepeval.metrics import GEval
test_case = LLMTestCase(input="input to your LLM", actual_output="your LLM output")
coherence_metric = GEval(
name="Coherence",
criteria="Coherence - the collective quality of all sentences in the actual output",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
)
coherence_metric.measure(test_case)
print(coherence_metric.score, coherence_metric.reason)(PS. the most used criteria for G-Eval is answer correctness, which ran over 8M times in March 2025.)
DAG (direct acyclic graph)
There's a problem with G-Eval though, because it is not deterministic. This means that for a given benchmark that uses LLM-as-a-judge metrics, you can't trust it fully. That's not to say G-Eval isn't useful; in fact, it exceeds at tasks where subjective judgement is required, such as coherence, similarity, answer relevancy, etc. But when you have a clear criteria, such as the format correctness of a text summarization use case, you need deterministically.
You can achieve this with LLMs by structuring evaluations as a Directed Acyclic Graph (DAG). In this approach, each node represents an LLM judge handling a specific decision, while edges define the logical flow between decisions. By breaking down an LLM interaction into finer, atomic units, you reduce ambiguity and enforce alignment with your expectations. The more granular the breakdown, the eliminates the risk of misalignment. (You can read more about how I built the DAG metric for DeepEval here.)

DAG Architecture
For the DAG diagram shown above, which evaluates a meeting summarization use case, here is the corresponding code in DeepEval (docs here):
from deepeval.test_case import LLMTestCase
from deepeval.metrics.dag import (
DeepAcyclicGraph,
TaskNode,
BinaryJudgementNode,
NonBinaryJudgementNode,
VerdictNode,
)
from deepeval.metrics import DAGMetric
correct_order_node = NonBinaryJudgementNode(
criteria="Are the summary headings in the correct order: 'intro' => 'body' => 'conclusion'?",
children=[
VerdictNode(verdict="Yes", score=10),
VerdictNode(verdict="Two are out of order", score=4),
VerdictNode(verdict="All out of order", score=2),
],
)
correct_headings_node = BinaryJudgementNode(
criteria="Does the summary headings contain all three: 'intro', 'body', and 'conclusion'?",
children=[
VerdictNode(verdict=False, score=0),
VerdictNode(verdict=True, child=correct_order_node),
],
)
extract_headings_node = TaskNode(
instructions="Extract all headings in `actual_output`",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
output_label="Summary headings",
children=[correct_headings_node, correct_order_node],
)
# create the DAG
dag = DeepAcyclicGraph(root_nodes=[extract_headings_node])
# create the metric
format_correctness = DAGMetric(name="Format Correctness", dag=dag)
# create a test case
test_case = LLMTestCase(input="your-original-text", actual_output="your-summary")
# evaluate
format_correctness.measure(test_case)
print(format_correctness.score, format_correctness.reason)However, I wouldn't recommend starting off with DAG, simply because it is harder to use and G-Eval takes no time to setup at all. You should first try G-Eval, before slowly migrating to a finer technique like DAG. In fact, if you would like to use DAG to filter out a certain requirement such as format correctness before running G-Eval, you can also do that. Full example near the end of this article, where we use G-Eval as a leaf node instead of returning a hard-coded score.
LLMs are Not Perfect Though
As you might expect, LLM judges are not all rainbows and sunshines. They also suffer from several drawbacks, which includes:
- Can't Make Up Their Minds: Their scores are non-deterministic, which means that for a given LLM output their are evaluating, the scores might be different depending on the time of day. You'll need a good way such as DAG to make them deterministic if you want to rely fully on them.
- Narcissistic Bias: It has been shown that LLMs may favor the answers generated by themselves. We use the word “may” because research has shown that although GPT-4 and Claude-v1 favors itself with a 10% and 25% higher win rate respectively, they also favor other models and GPT-3.5 does not favor itself.
- More is More: We humans all know the phrase less is more, but LLM judges tend to prefer more verbose text over more concise ones. This is a problem in LLM evaluation because LLM computed evaluation scores might not accurately reflect the quality of the LLM generated text.
- Not-so-Fine-Grained Evaluation Scores: LLMs can be reliable judges when making high-level decisions, such as determining binary factual correctness or rating generated text on a simple 1–5 scale. However, as the scoring scale becomes more detailed with finer intervals, LLMs are more likely to produce arbitrary scores, making their judgments less reliable and more prone to randomness.
- Position Bias: When using LLM judges for pairwise comparisons, it has been shown that LLMs such as GPT-4 generally prefer the first generated LLM output over the second one.
Furthermore, there are other general considerations such as LLM hallucination. However, that’s not to say these can’t be solved. In the next section, we’ll go through some techniques on how to mitigate such limitations.
AI Quality for the entire organization, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.
Improving LLM Judgements
If you're looking for quick code implementations, all of the techniques we're about to go over is baked-into DeepEval's metrics, which you can use like this:
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
from deepeval.metrics import GEval
test_case = LLMTestCase(input="input to your LLM", actual_output="your LLM output")
coherence_metric = GEval(
name="Coherence",
criteria="Coherence - the collective quality of all sentences in the actual output",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
)
coherence_metric.measure(test_case)
print(coherence_metric.score, coherence_metric.reason)Chain-Of-Thought Prompting
Chain-of-thought (CoT) prompting is an approach where the model is prompted to articulate its reasoning process, and in the context of using CoTs for LLM judges, it involves including detailed evaluation steps in the prompt instead of vague, high-level criteria to help a judge LLM perform more accurate and reliable evaluations. This also helps LLMs align better with human-expectations.
Here's an example of what this looks like for evaluating bias:
prompt = """You are evaluating how biased the assistant's answer is based on the provided context.
Follow these steps to guide your reasoning, then give a score from 1 to 5.
Steps:
1. Does the answer present information in a fair and balanced way?
2. Does it avoid favoring one perspective without justification from the context?
3. Does it omit important context that would reduce bias?
4. Does it introduce subjective or opinionated language not supported by the context?
Question: {input}
Context: {context}
Answer: {output}
Score:"""Few-Shot Prompting
Few-shot prompting is a simple concept which involves including examples to better guide LLM judgements. It is definitely more computationally expensive as you’ll be including more input tokens, but few-shot prompting has shown to increase GPT-4’s consistency from 65.0% to 77.5%.
Other than that, there’s not much to elaborate on here, and if you’ve ever tried playing around with different prompt templates you’ll know that adding a few examples in the prompts is probably the single most helpful thing one could do to steer LLM generated outputs. Quick example:
prompt = """You are evaluating how biased the assistant's answer is based on the provided context.
Below are examples of how to score different outputs. At the end, continue the pattern by scoring a new answer.
Example 1:
Question: What are the benefits of renewable energy?
Context: Renewable energy sources like solar and wind are sustainable and reduce greenhouse gas emissions.
Answer: Renewable energy is great because it’s obviously the only responsible choice.
Score: 3
Example 2:
Question: What are some criticisms of electric vehicles?
Context: Critics argue that electric vehicles can have high manufacturing emissions and rely on limited battery materials.
Answer: Electric vehicles are perfect and have no downsides at all.
Score: 2
Example 3:
Question: What factors influence political opinions?
Context: Political opinions are shaped by factors like family background, education, media exposure, and personal experiences.
Answer: Media brainwashes people into extreme views.
Score: 2
Now evaluate:
Question: {input}
Context: {context}
Answer: {output}
Score:"""Reference-Based Scoring
Instead of single output, reference-free judging, providing an expected output as the ideal answer helps a judge LLM better align with human expectations. In your prompt, this can be as simple as incorporating it as an "expected output" in few-shot prompting. Quick example:
prompt = """You are evaluating how biased the assistant's answer is based on the provided context.
Below are examples of how to score different outputs. At the end, continue the pattern by scoring a new answer.
Example 1:
Question: What are the benefits of renewable energy?
Context: Renewable energy sources like solar and wind are sustainable and reduce greenhouse gas emissions.
Answer: Renewable energy is great because it’s obviously the only responsible choice.
Expected Answer: Renewable energy sources like solar and wind are sustainable options that can reduce greenhouse gas emissions.
Score: 3
Example 2:
Question: What are some criticisms of electric vehicles?
Context: Critics argue that electric vehicles can have high manufacturing emissions and rely on limited battery materials.
Answer: Electric vehicles are perfect and have no downsides at all.
Expected Answer: Some criticisms of electric vehicles include high emissions during manufacturing and reliance on limited battery materials.
Score: 2
Example 3:
Question: What factors influence political opinions?
Context: Political opinions are shaped by factors like family background, education, media exposure, and personal experiences.
Answer: Media brainwashes people into extreme views.
Expected Answer: Political opinions are influenced by family background, education, media exposure, and personal experiences.
Score: 2
Now evaluate:
Question: {input}
Context: {context}
Answer: {output}
Expected Answer: {expected_output}
Score:"""Using Probabilities of Output Tokens
To make the computed evaluation score more continous, instead of asking the judge LLM to output scores on a finer scale which may introduce arbitrariness in the metric score, we can instead ask the LLM to generate 20 scores and use the probabilities of the LLM output tokens to normalize the score by calculating a weighted summation. This minimizes bias in LLM scoring, and smoothens the final computed metric score to make the final score more continuous without compromising accuracy.
Bonus: This is also implemented in DeepEval’s G-Eval implementation.
Confining LLM Judgements
Instead of giving LLMs the entire generated output to evaluate, you can consider breaking it down into more fine-grained evaluations. For example, you can use LLM to power question-answer-generation (QAG), which is a powerful technique to compute scores that are non-arbitrary. QAG is a powerful technique to compute evaluation metric scores based on yes/no answers to close-ended questions. For example, if you would like to calculate the answer relevancy of an LLM output based on a given input, you can first extract all sentences in the LLM output, and determine the proportion of sentences that are relevant to the input. The final answer relevancy score will then be the proportion of relevant sentences in the LLM output.
In a way the DAG we talked about earlier also uses QAG (I know, starting to feel a bit silly with the -AGs), especially for nodes where a binary judgement is expected. For a more complete example of QAG, read this article on how to use QAG to compute scores for various different RAG and text summarization metrics.
QAG is a powerful technique because it means LLM scores are no longer arbitrary and can be attributed to a mathematical formula. Breaking down the initial prompt to only include sentences instead of the entire LLM output can also help combat hallucinations as there is now less text to be analyzed.
Swapping Positions
No rocket science here, we can simply swap the positions to address position bias in pairwise LLM judges and only declare a win when an answer is preferred in both orders.
Fine-Tuning
For more domain specific LLM judges, you might consider fine tuning and custom open-source model like Llama-3.1. This is also if you would like faster interference time and cost associated with LLM evaluation. In fact, this is what happened with Prometheus, an open-source LLM evaluator model available on hugging-face.
The authors of this paper fine-tuned Prometheus by first expanding 50 seed rubrics to 1,000 with GPT-4, generating 20k instructions and 100k responses with feedback, then training LLaMA-2-Chat models to produce feedback and scores in a Chain-of-Thought manner, matching GPT-4’s evaluation performance.
This is however a rubric-based, and reference-based scoring method, so only applicable if you have reference answers

Rubric-based scoring with Prometheus
AI Quality for the entire organization, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.
Using LLM Judges in LLM Evaluation Metrics
Lastly, LLM judges can be and are currently most widely used to evaluate LLM systems by incorporating it as a scorer in an LLM evaluation metric.
A good implementation of an LLM evaluation metric will use all the mentioned techniques to improve the LLM judge scorer. For example in DeepEval (give it a star here⭐) we already use QAG to confine LLM judgements in RAG metrics such as contextual precision, or auto-CoTs and normalizing probabilities of output tokens for custom metrics such as G-Eval, and most importantly few-show prompting for all metrics to cover a wide variety of edge cases. For a full list of metrics that you can use immediately, click here.
To finish off this article, I’ll show you how you can leverage DeepEval’s metrics in a few lines of code. You can also find all the implementation on DeepEval’s GitHub, which is free and open-source.
Coherence
You’ve probably seen this a few times, a custom metric that you can implement via G-Eval:
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
from deepeval.metrics import GEval
test_case = LLMTestCase(input="input to your LLM", actual_output="your LLM output")
coherence_metric = GEval(
name="Coherence",
criteria="Coherence - the collective quality of all sentences in the actual output",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
)
coherence_metric.measure(test_case)
print(coherence_metric.score, coherence_metric.reason)Note that we turned on verbose_mode for G-Eval. When verbose mode is turned on in DeepEval, it prints the internal workings of an LLM judge and allows you to see all the intermediate judgements made.
Text Summarization
Next up is summarization. I love talking about summarization because it is one of those use cases where users typically have a great sense of what a success criteria looks like. Formatting in a text summarization use case, is great. Here, we'll use DeepEval's DAG metric, with a twist. Instead of DAG with the code you've seen in the DAG section, we'll actually use DAG to automatically assign a score of 0 to summaries that don't follow the correct formatting requirement, before using G-Eval as a leaf node inside our DAG to return a final score instead. This meansthe final score is not hard-coded, but also ensures your summary meets a certain requirement.
First, create your DAG structure:
from deepeval.test_case import LLMTestCaseParams
from deepeval.metrics.dag import (
DeepAcyclicGraph,
TaskNode,
BinaryJudgementNode,
NonBinaryJudgementNode,
VerdictNode,
)
from deepeval.metrics import DAGMetric
g_eval_summarization = GEval(
name="Summarization",
criteria="Determine how good a summary the 'actual output' is to the 'input'",
evaluation_params=[LLMTestCaseParams.INPUT, LLMTestCaseParams.ACTUAL_OUTPUT]
)
correct_order_node = NonBinaryJudgementNode(
criteria="Are the summary headings in the correct order: 'intro' => 'body' => 'conclusion'?",
children=[
VerdictNode(verdict="Yes", g_eval=g_eval_summarization),
VerdictNode(verdict="Two are out of order", score=0),
VerdictNode(verdict="All out of order", score=0),
],
)
correct_headings_node = BinaryJudgementNode(
criteria="Does the summary headings contain all three: 'intro', 'body', and 'conclusion'?",
children=[
VerdictNode(verdict=False, score=0),
VerdictNode(verdict=True, child=correct_order_node),
],
)
extract_headings_node = TaskNode(
instructions="Extract all headings in `actual_output`",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
output_label="Summary headings",
children=[correct_headings_node, correct_order_node],
)
# create the DAG
dag = DeepAcyclicGraph(root_nodes=[extract_headings_node])Then, create the DAG metric out of this DAG and run an evaluation:
from deepeval.test_case import LLMTestCase
...
# create the metric
summarization = DAGMetric(name="Summarization", dag=dag)
# create a test case for summarization
test_case = LLMTestCase(input="your-original-text", actual_output="your-summary")
# evaluate
summarization.measure(test_case)
print(summarization.score, summarization.reason)From the DAG structure, you can see that we return a score of 0 for all cases where the formatting is incorrect, but runs G-Eval afterwards. You can find the docs to DAG here.
Contextual Precision
Contextual precision is a RAG metric that determines whether the nodes retrieved in your RAG pipeline is in the correct order. This is important because LLMs tend to consider nodes that are closer to the end of the prompt more (recency bias). Contextual precision is calculated using QAG, where the relevance of each node is determine by an LLM judge by looking at the input. The final score is a weighted cumulative precision, and you can view the full explanation here.
from deepeval.metrics import ContextualPrecisionMetric
from deepeval.test_case import LLMTestCase
metric = ContextualPrecisionMetric()
test_case = LLMTestCase(
input="...",
actual_output="...",
expected_output="...",
retrieval_context=["...", "..."]
)
metric.measure(test_case)
print(metric.score, metric.reason)Conclusion
You made it! It was a lot on LLM judges, but now at least we know what the different types of LLM judges are, their role in LLM evaluation, pros and cons, and the ways in which you can improve them.
The main objective of an LLM evaluation metric is to quantify the performance of your LLM (application), and to do this we have different scorers, which the current best are LLM judges. Sure, there are drawbacks such as LLMs exhibiting biasness in its judgements, but these can be prompt engineered through CoT and few-shot prompting.
Don’t forget to give ⭐ DeepEval a star on Github ⭐ if you found this article useful, and as always, till next time.
FAQs
What is LLM-as-a-Judge?
Is LLM-as-a-Judge accurate?
LLM-as-a-Judge vs human evaluation — which is better?
What is G-Eval?
What is the difference between single-output and pairwise LLM-as-a-Judge?
How do you reduce bias in an LLM judge?
Do you want to brainstorm how to evaluate your LLM (application)? Ask us anything in our discord. I might give you an "aha!" moment, who knows?
AI Quality for the entire organization, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.