
.svg)
.svg)




Manually evaluating LLM systems is tedious, time-consuming and frustrating, which is why if you’ve ever found yourself looping through a set of prompts to manually inspect each corresponding LLM output, you’ll be happy to know that this article will teach you everything you need to know about LLM evaluation to ensure the longevity of you and your LLM application.
LLM evaluation refers to the process of ensuring LLM outputs are aligned with human expectations, which can range from ethical and safety considerations, to more practical criteria such as the correctness and relevancy of LLM outputs. From an engineering perspective, these LLM outputs can often be found in the form of unit test cases, while evaluation criteria can be packaged in the form of LLM evaluation metrics.
On the agenda, we have:
- What is the difference between LLM and LLM system evaluation, and their benefits
- Offline evaluations, what are LLM system benchmarks, how to construct evaluation datasets and choose the right LLM evaluation metrics (powered by LLM-as-a-judge), and common pitfalls
- Real-time evaluations, and how they are useful in improving benchmark datasets for offline evaluations
- Real-world LLM system use cases and how to evaluate them, featuring chatbotQA and Text-SQL
Let’s begin.
LLM vs LLM System Evaluation
Let’s get this straight: While an LLM (Large Language Model) refers specifically to the model (eg., GPT-4) trained to understand and generate human language, an LLM system refers to the complete setup that includes not only the LLM itself but also additional components such as function tool calling (for agents), retrieval systems (in RAG), response caching, etc., that makes LLMs useful for real-world applications, such as customer support chatbots, autonomous sales agents, and text-to-SQL generators.
However, it’s important to note that an LLM system can sometimes simply be composed of the LLM itself, as is the case with ChatGPT. Here is an example RAG-based LLM system that performs the Text-SQL task:
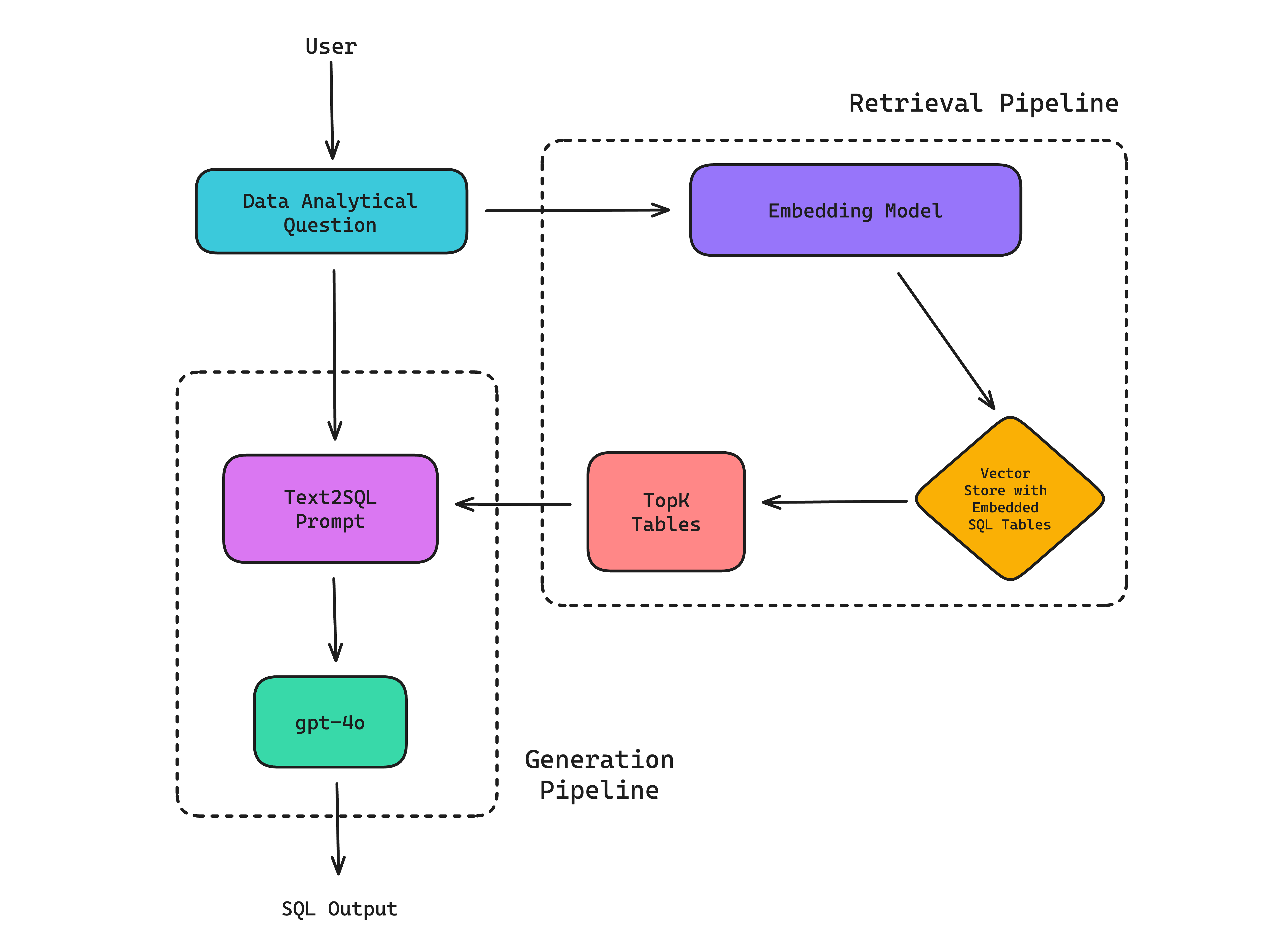
Since the primary goal of Text-SQL is to generate correct and efficient SQL for a given user query, the user query is usually first used to fetch the relevant tables in a database schema via a retrieval pipeline before using it as context to generate the correct SQL via a SQL generation pipeline. Together, they make up a (RAG-based) LLM system.
(Note: Technically, you don’t have to strictly perform a retrieval before generation, but even for a moderately sized database schema it is better to perform a retrieval to help the LLM hallucinate less.)
Evaluating an LLM system, is therefore not as straightforward as evaluating an LLM itself. While both LLMs and LLM systems receive and generate textual outputs, the fact that there can be several components working in conjunction in an LLM system means you should apply LLM evaluation metrics more granularly to evaluate different parts of an LLM system for maximum visibility into where things are going wrong (or right).
For example, you can apply a contextual recall metric to evaluate the retrieval pipeline in the Text-SQL example above to assess whether it is able to retrieve all necessary tables needed to answer a particular user query.
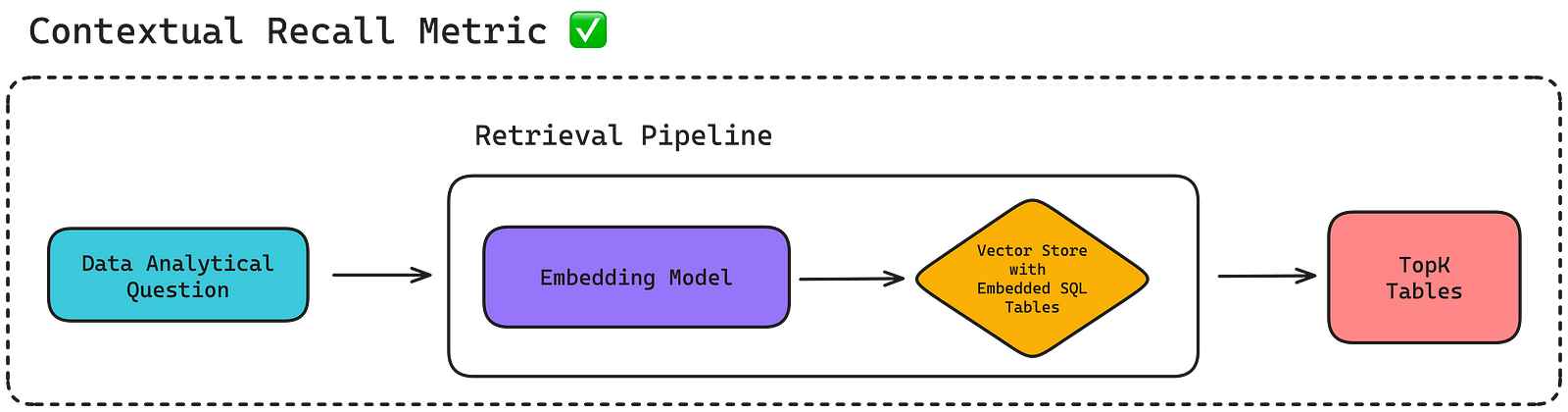
Similarly, you can also apply a custom SQL correctness metric implemented via G-Eval to evaluate whether the generation pipeline generates the correct SQL based on the top-K data tables retrieved.
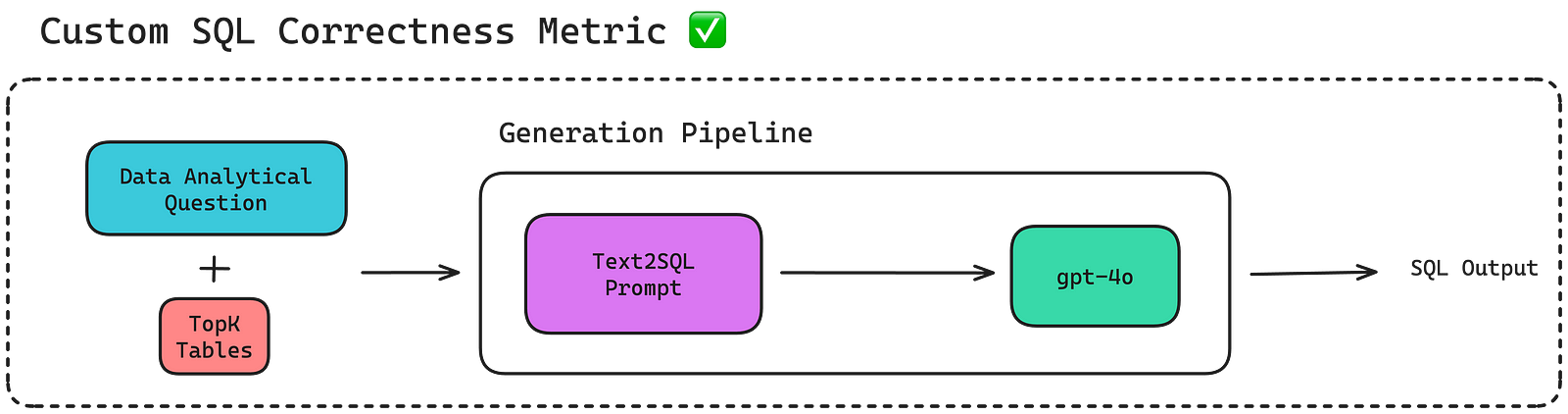
In summary, an LLM system is composed of multiple components that help make an LLM more effective in carrying out its task as shown in the Text-SQL example, and it is harder to evaluate because of its complex architecture.
In the next section, we will see how we can perform LLM system evaluation in development (aka. offline evaluations), including ways in which we can quickly create large amounts of test cases to unit test our LLM system, and how to pick the right LLM evaluation metrics for certain components.

Confident AI: The DeepEval LLM Evaluation Platform
The leading platform to evaluate and test LLM applications on the cloud, native to DeepEval.
.png)


Got Red? Safeguard LLM Systems Today with Confident AI
The leading platform to red-team LLM applications for your organization, powered by DeepTeam.
Offline Evaluations: Test Cases, Evaluation Datasets, LLM Metrics and Benchmarks
Offline evaluations refers to evaluating or testing your LLM system in a local development setup. Imagine running evaluations in your local development environment which can be anything from a Python script, Colab/Jupyter Notebooks, to CI/CD pipelines on Github Actions before deploying to production. This allows you to quantitatively improve your LLM system architecture, or even iterate on the perfect set of hyperparameters for your LLM system (such as the LLM used, prompt templates, embedding model, etc. used in for each component).
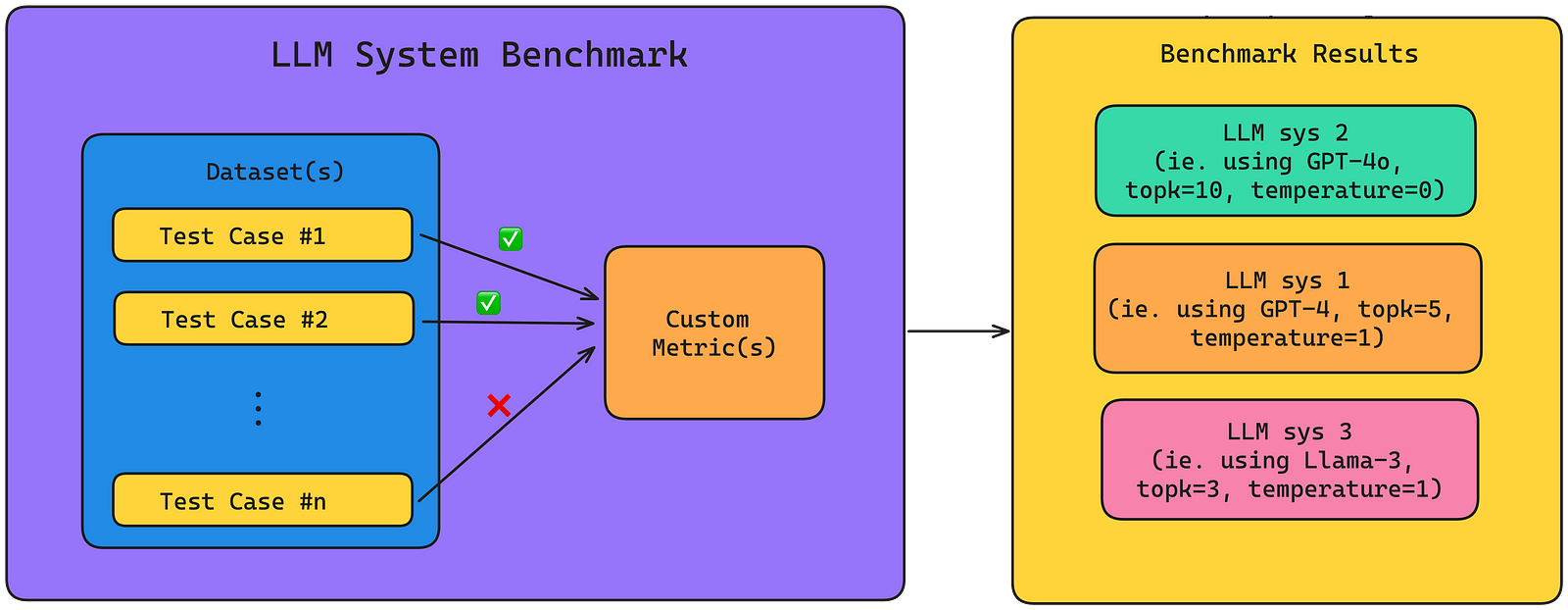
Some engineers also call this “benchmarking” an LLM system, which is not wrong at all. Benchmarking LLM systems refers to the process of quantifying LLM system performance on a set of custom criteria aided by LLM evaluation metrics on a standardized evaluation dataset, which is exactly how offline evaluations is carried out. Sticking to the Text-SQL example in the previous section, the metrics used to benchmark our LLM system would be the contextual recall and custom SQL correctness metric, and they would be used to quantify how well the Text-SQL LLM system is performing based on a set of user queries and SQL outputs, which we call test cases.
Terminology wise, here’s what you need to know:
- Benchmarks are made up of (usually one) evaluation dataset and LLM evaluation metrics.
- An evaluation dataset is made up of test cases, which is what LLM evaluation metrics will be applied to.
- There can be multiple LLM evaluation metrics for a single benchmark, each evaluating different parts of an LLM system for each test case.
You can then run these LLM system benchmarks in your local development environment each time you make changes to your LLM system (eg., switching to a different retrieval architecture, or LLM provider) to detect any breaking changes in performance, or even run these benchmarks in your CI/CD pipeline to regression test your LLM system.
Before moving on to the next section, here is a spoiler on how you can get everything setup in code using ⭐DeepEval⭐, the open-source LLM evaluation framework:
And for those who want to start evaluating immediately, checkout the DeepEval quick-start guide.
Evaluation Datasets and Test Cases
An evaluation dataset is a collection of test cases. An evaluation dataset is a collection of test cases. And no, I did not mistype the same sentence twice.
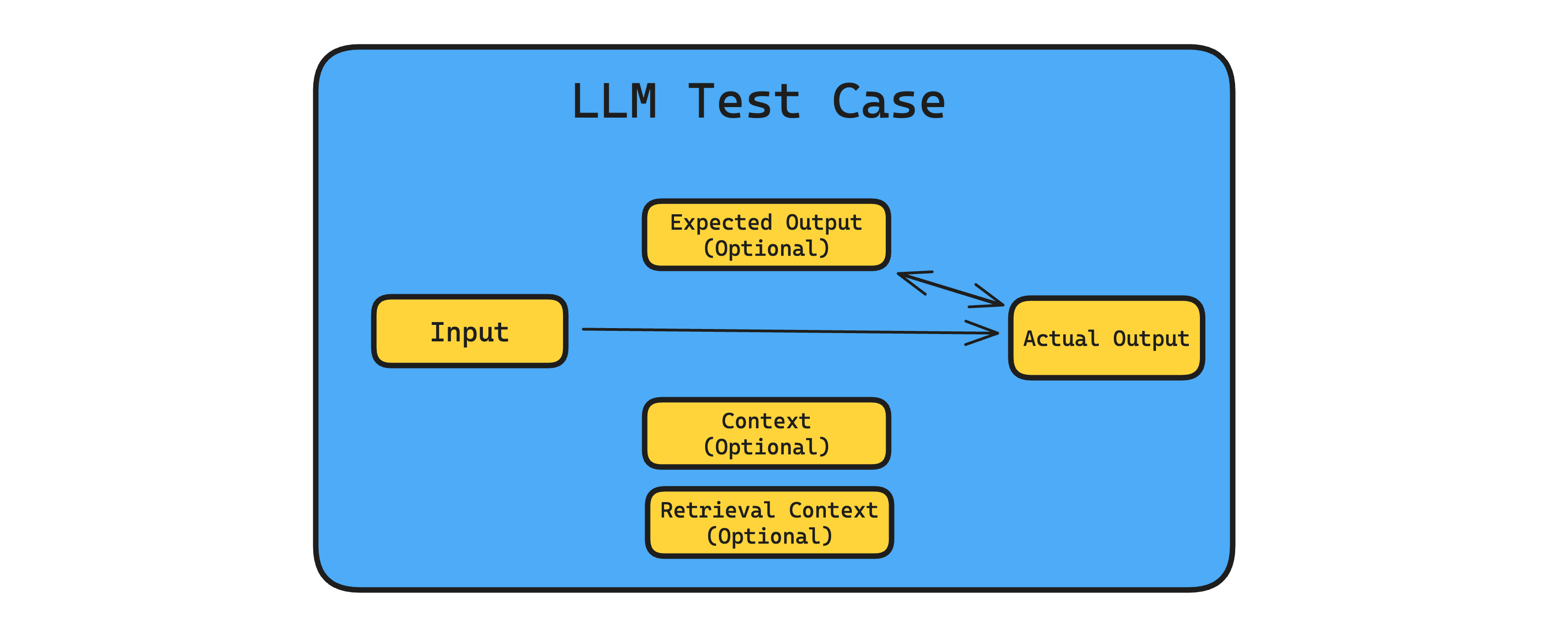
A test case is simply a unit that holds the relevant data for you to unit test your LLM system on. Here are all the parameters an LLM test case contains:
- Input — the input to your LLM system.
- Actual output — the text response generated by your LLM system.
- Expected output — the ideal response for a given input to your LLM system.
- Retrieval Context — the text chunks / documents retrieved in a RAG pipeline / retrieval system.
- Context — the ideal text chunks / documents that the expected output is derived from.
Here’s the catch: different metrics requires different parameters to be populated in an LLM test case. For example, a reference-less answer relevancy metric (which you’ll learn later) will only require the input and actual output, while a reference-based answer relevancy metric will require the input, actual output, and expected output.
Another example can be found in the original contextual recall metric used earlier in the Text-SQL example. Since contextual recall assess whether your retrieval system is able to retrieve all the relevant text chunks to answer a certain query, you’ll need the input (ie. the query) and retrieval context (ie. the relevant text chunks that were retrieved).
Here are some fast rules you’ll want to follow when preparing an evaluation dataset:
- Start with 50–100 test cases. You can either curate these from scratch or take it from production data (if your LLM system is already in production). From experience, this number works best because it is enough to uncover weaknesses in your LLM system while not too overwhelming of a number to start with.
- Curate test cases that are most likely to fail on whatever criteria you have decided to evaluate your LLM system on.
- Actual outputs does not have to be precomputed, especially if you wish to regression test your LLM system for every change you make.
- Populate test cases with expected outputs. As explain in the LLM metrics section, reference-based metrics give much more accurate results, which is why you’ll need expected outputs.
Although I’ve stressed why it is important to prepare test cases with expected outputs, it is definitely not an easy task, especially for 50–100 test cases. Currently there are two main ways to curate evaluation datasets for your LLM system benchmark:
- Human annotation — this one’s straightforward, hire someone to sit down and prepare 100 test cases. You can also curate test cases from production data if your LLM system is already live in production.
- Synthetic data generation — slightly more complicated, use LLMs to generate 100 test cases instead.
I’d love to write a step-by-step guide on how to hire someone on Upwork, but for this article I’ll be touching on synthetic data generation using LLMs instead. Synthetic data generation using LLMs involves supplying an LLM with context(yes, the same context in an LLM test case as outlined above), and generating a corresponding input and expected output based on the given context.
For example, in a Text-SQL use case, a great synthetic data generator would:
- Randomly (to add variety to your evaluation dataset) select different data tables in your database schema and use them as context to your test case.
- Generate a user query as input to your test case.
- Generate an expected output based on the context and input of your test case.
- Repeat until you have a reasonably sized evaluation dataset.
However, you’ll also need to evolve your test case inputs to make them more realistic / indistinguishable from human annotated datasets. This is known as evolution, which is a technique used to make generated synthetic data more realistic, which was originally introduced in the Evol-Instruct paper by Microsoft.
In fact, here is a great article on how to build your own synthetic data generator if you’re interested in how synthetic data generation works with LLMs, but if you want someone that is already production tested and open-source here is a quick way to generate synthetic data using LLMs via DeepEval:
Notice that in DeepEval we are generating “goldens”, which are basically test cases but without actual outputs. This means you’ll need to run your LLM system to generate actual outputs for each golden at evaluation time to make them viable LLM test cases.
LLM Metrics
LLM evaluation metrics are used to help automate the process of evaluating LLM systems. Sure, you can have human evaluators evaluate LLM systems for you, but at that point you will just be back to inefficiently vibe checking LLM outputs. So the question is, how do I build my own LLM evaluation metric, or which LLM evaluation metrics should I used for my LLM system?
In one of my previous articles, I talked in great detail on everything you need to know about LLM evaluation metrics, but in summary, traditional metrics such as BERT, ROUGE, and n-gram doesn’t work because LLM outputs are too complex for statistical methods or non-LLM-models to evaluate, and so the solution is to resort to using LLMs-as-a-judge.
LLM-as-a-judge involves using LLMs to score test cases. You may be skeptical at first, but research has shown that using LLMs to evaluate LLMs is the closest we can get to human correlation.
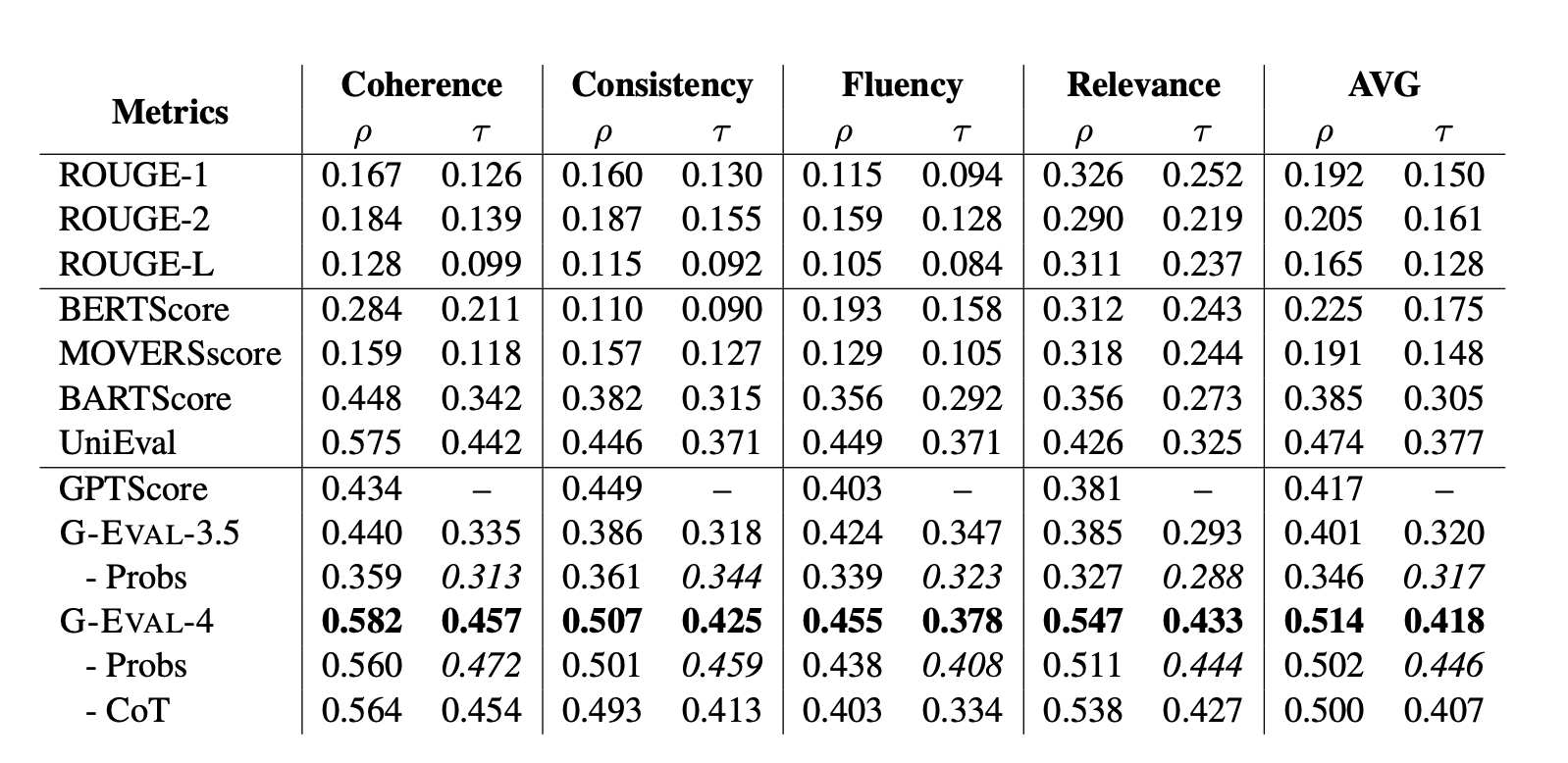
Moreover, techniques such as G-Eval, prompting to reduce the size of the text to be evaluated in a test case, or using QAG (Question Answer Generation) to more mathematically calculate a metric score for each test case, helps LLMs to produce scores that are much more aligned with human expectations. (I would highly recommend reading this article if you are in any way confused or simply want to learn more about using LLMs to evaluate LLMs.)
Here is the list of the most commonly used LLM evaluation metrics for LLM systems, each evaluating different parts of an LLM system:
- Correctness
- Answer Relevancy
- Faithfulness
- Similarity
- Coherence
- Contextual Recall
- Contextual Relevancy
- Contextual Precision
- Bias
- Toxicity
(DeepEval supports each metric out-of-the-box, and you should visit the docs to learn more about each individual metric and when it should be used.)
For example, here is how you can implement a custom LLM-as-a-judge “correctness” metric in code:
When running evaluations in development, you should also aim to use REFERENCE-BASED metrics. Reference-based metrics are metrics that score based on some labelled, golden, ideal, expected output in a test case. Consider the answer relevancy metric for example, which can be both a reference-less and reference-based metric:
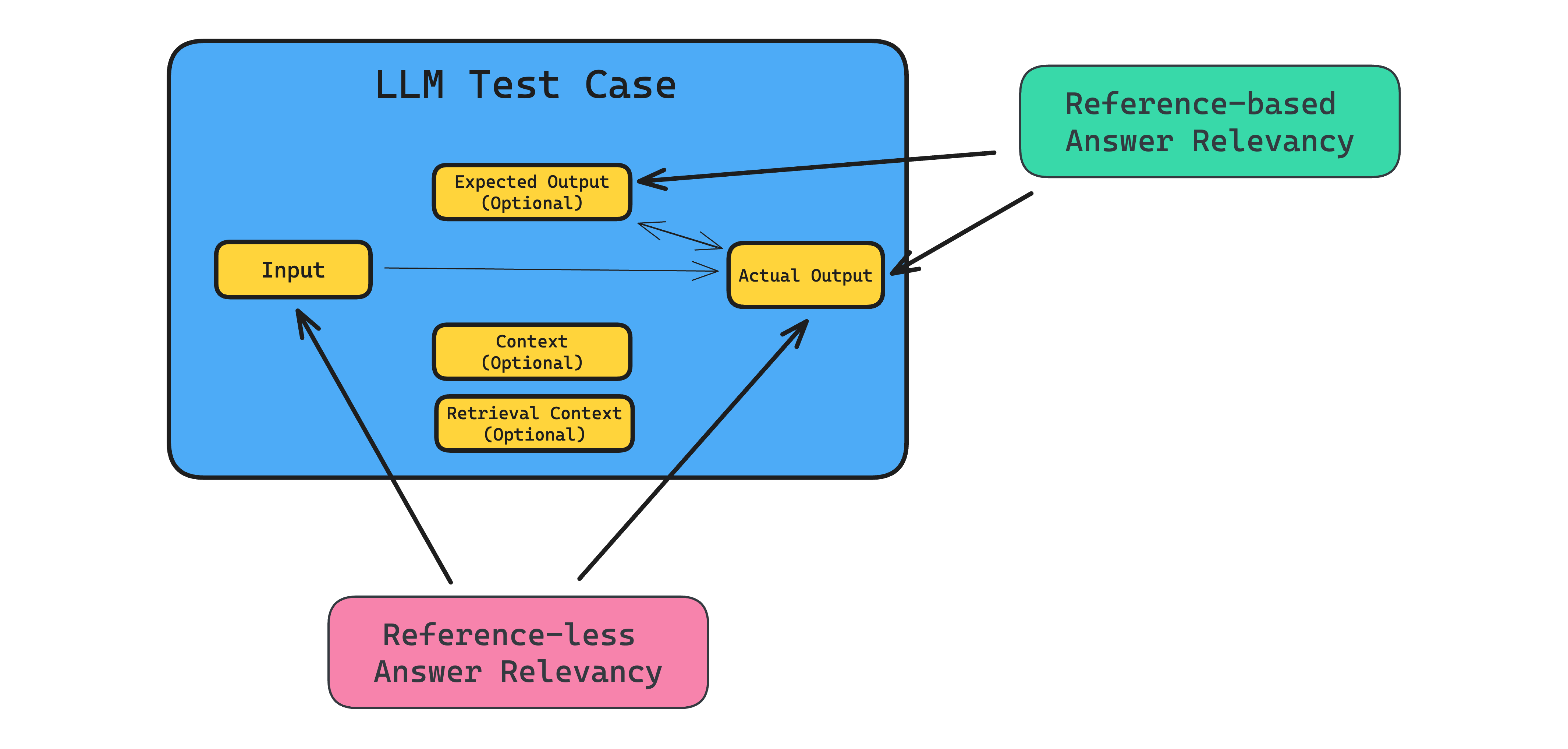
Although you can definitely compute the answer relevancy metric score by using an LLM to assess how relevant an LLM output is compared to the corresponding input, a better approach would be to have expected outputs and compare it to the generated LLM output instead. This is because reference-less metrics usually has a “looser” rubric, and so LLM computed metric scores are more likely to fluctuate more for the same set of test cases in a benchmark when compared to reference-based metrics. In other words, reference-based metrics are more reliable.
Sure, it takes more time and effort to curate evaluate datasets and populate each test case with expected outputs, but having supported hundreds of LLM evaluation use cases through DeepEval I can say with certainty that it definitely helps test LLM systems more accurately.
The good news is, in the next section I’ll show how you can semi-automate this process by generating synthetic datasets/test cases using an LLM.
Confident AI: The DeepEval LLM Evaluation Platform
The leading platform to evaluate and test LLM applications on the cloud, native to DeepEval.
Got Red? Safeguard LLM Systems Today with Confident AI
The leading platform to red-team LLM applications for your organization, powered by DeepTeam.
Benchmarks
Benchmarks are made up of evaluation datasets and LLM metrics and unlike typical LLM benchmarks, all LLM system benchmarks are custom. This is because:
- There is no standard LLM evaluation metrics for LLM systems (even for a given use case like Text-SQL), because the metrics depends on the exact architecture of an LLM system, and there is no standard architecture for any single use case.
- There is no standard set of test cases/evaluation dataset for a given use case. For example, you will need two different evaluation datasets for two different database schemas for a Text-SQL use case since user queries and golden SQL outputs in test cases will be different.
(For those interested in learning more about pure LLM benchmarks such as MMLU, DROP, and HellaSwag, here is another great article.)
And before I forget, here is how you can benchmark your LLM system in code using the answer relevancy metric:
Common Pitfalls in Offline Evaluation
The biggest mistake one can make, is to assume your benchmark dataset is “good enough”, and to never improve on it over time. Improving your benchmark dataset is crucial because for your benchmark to make sense it should always reflect what the most recent vulnerabilities are in your LLM application.
In the next section, I’ll show how you can improve your benchmark evaluation dataset over time as you move your LLM system into production.
Real-time Evaluations
(If your LLM system is not in production, this section might be too early for you)
Offline evaluation is great for iterating, but it is limited by the comprehensiveness of your benchmark dataset. Although you can definitely have human annotators or data synthesizers curate more test cases based on data in your knowledge base, you’ll need to incorporate production data into your benchmark datasets to simulate how a real living user would truly interact with your LLM application.
Production data refers to the inputs and responses your LLM application receives and generates in a live production environment. But here’s a problem: you’ll most likely not have the time and resources to go through every single LLM response generated in production to determine which one of them should be added to your evaluation dataset.
Imagine a scenario where your LLM application generates 50k LLM responses in production a month. The chances are you won’t be able to go through all of them without losing your sanity. So you might resort to randomly sampling 10% of the generated responses, and manually go through them again, which is still an extremely taxing task. This is why real-time evaluations are valuable.
Real-time evaluations allow you to easily identify responses that are most likely to be unsatisfactory in production. Instead of randomly sampling 10% of responses generated in production, a robust real-time evaluation infrastructure could allow you to filter for LLM responses that are failing on certain criteria. It helps human evaluators improve your LLM system benchmark using production data in a much more efficient way.
LLM Metrics, in Production
In the previous LLM metrics section, we stressed that metrics in development should be reference-based metrics (ie. evaluates using the expected output on an LLM test case), because reference-based metrics helps benchmark scores to be more reliable due to a stricter scoring rubric.
However, reference-baed metrics cannot be executed in production, simply because there are no expected outputs for each generated LLM response. So, we’ll be resorting to reference-less metrics instead. Below is an example of a reference-less answer relevancy metric (which we initially introduced as a reference-based metric in the previous LLM metric section):
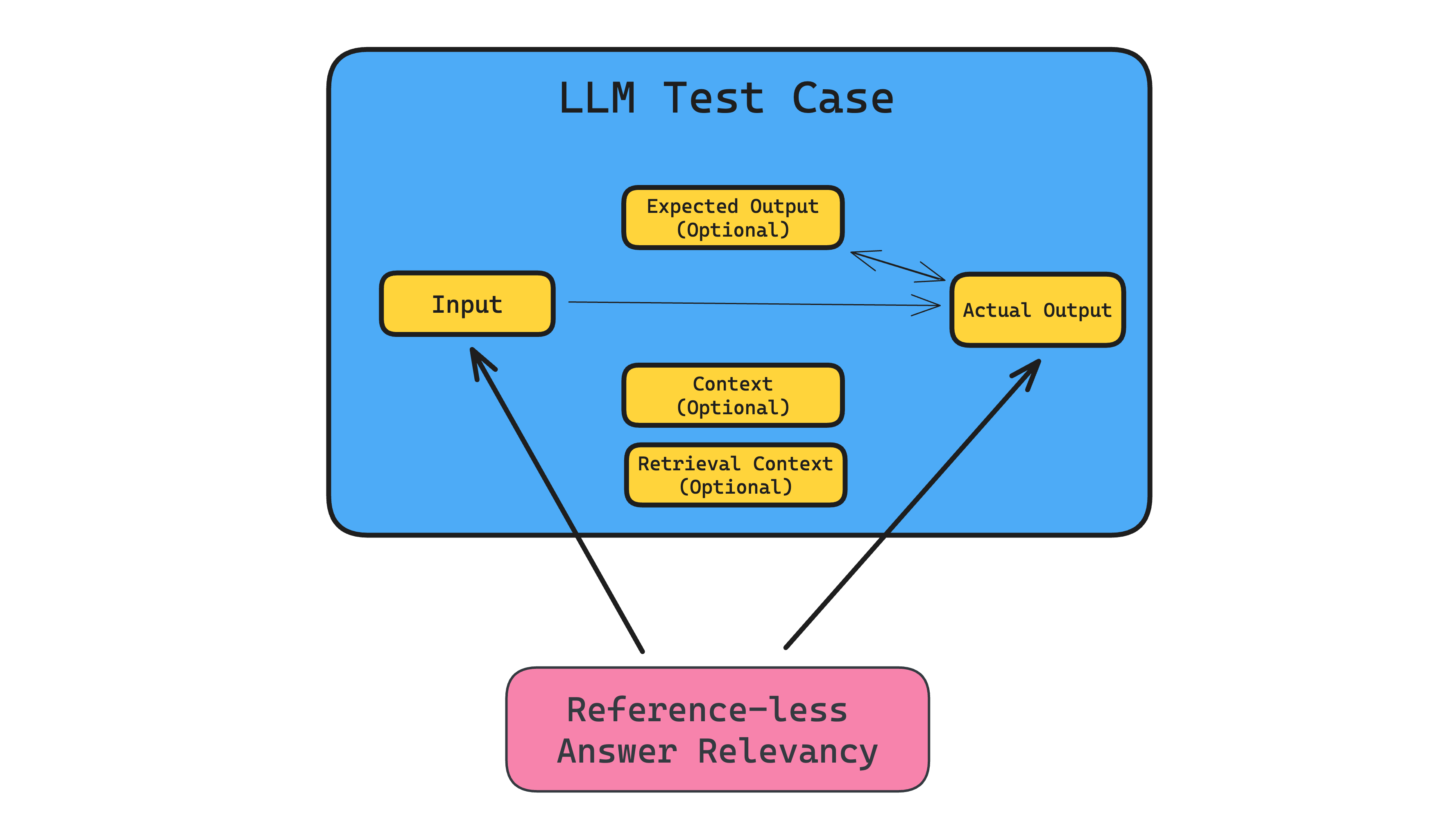
The idea is to pick one or many reference-less metrics, use it to evaluate each incoming LLM response, and use these metric scores to figure out which LLM response should be added to augment your existing benchmark dataset.
Lastly, if you’re looking for an all-in-one solution to run real-time evaluations and manage benchmarks on the cloud, try Confident AI. It is already fully integrated with DeepEval and allows synthetic data generation, literally any LLM evaluation metric, and an entire dedicated infrastructure to run real-time evaluations when monitoring LLM responses in production.
Confident AI: The DeepEval LLM Evaluation Platform
The leading platform to evaluate and test LLM applications on the cloud, native to DeepEval.
Got Red? Safeguard LLM Systems Today with Confident AI
The leading platform to red-team LLM applications for your organization, powered by DeepTeam.
Example Use Cases
To wrap things up, I’ve prepared two simple offline LLM evaluation examples for emerging LLM system use cases. For each example, we’re going to follow the following steps:
- Generating synthetic test cases for your benchmark dataset
- Choose the relevant LLM evaluation metrics
- Run the benchmark
Chatbot QA
A chatbot QA (question-answering) is basically a chat based information search engine, but different from ChatGPT because it is not conversational. Most often used to quickly search for information in a knowledge base, it uses a RAG-based approach to first retrieve the relevant information by performing a vector search in the vector store that contains parsed and index information from your knowledge base, before feeding this information to your LLM to generate an answer for a given user query:
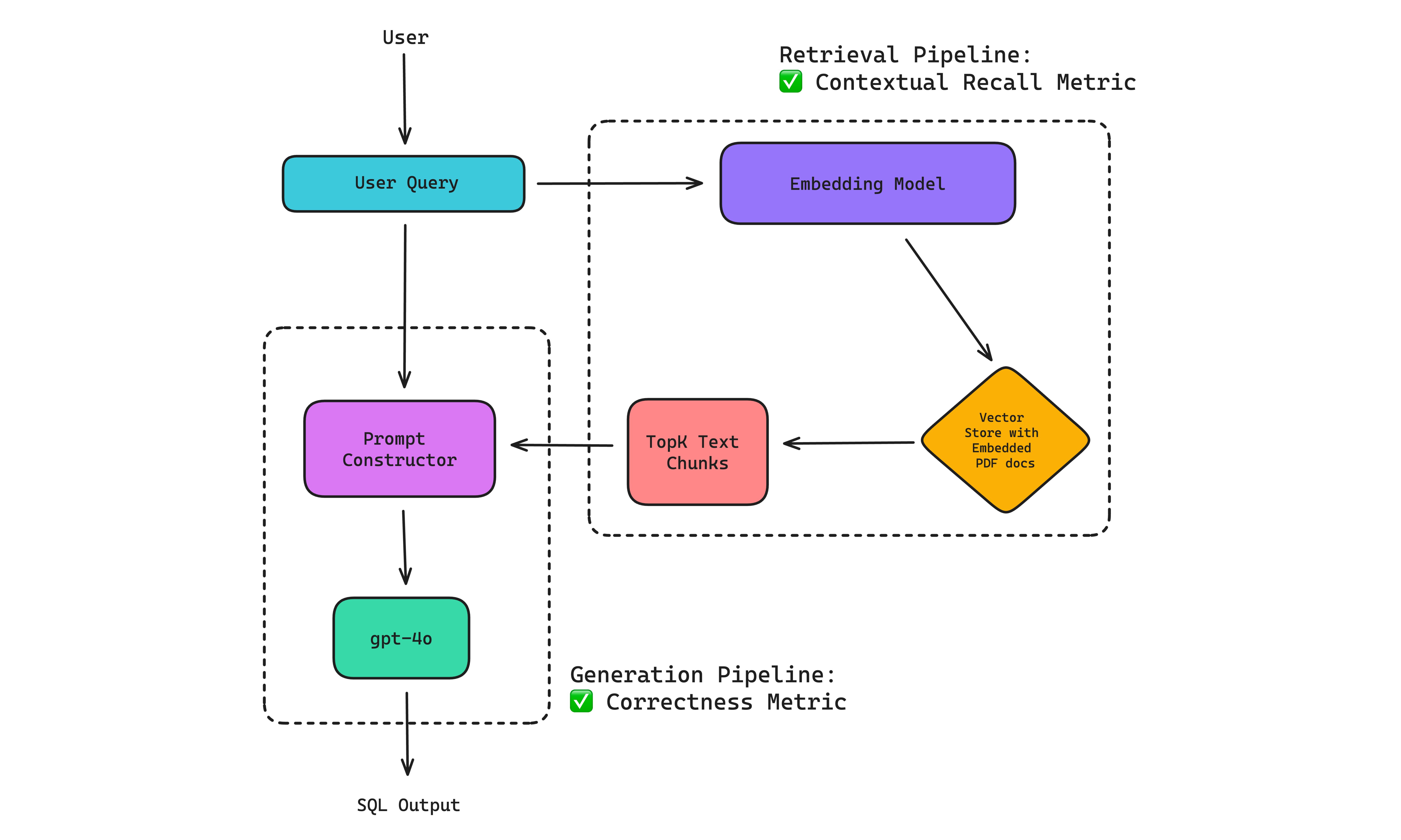
(Note: this diagram and the Text-SQL one looks almost identical since both use cases are a simplified RAG-based LLM system)
Step 1: Assuming we already have a few PDF documents representing our knowledge-base titled knowledge_1.pdf, knowledge_2.pdf, etc., we can generate synthetic test cases from these documents for our chatbot QA application:
(Link to synthesizer documentation here)
Step 2: Now that we have some synthetic data generated, we can define our metrics. For this example, we’ll just be using two metrics: Correctness and Contextual Recall.
(Link to metrics documentation here)
The G-Eval correctness metric compares the factual correctness of the actual output to the expected output, while contextual recall assesses whether the retrieval context contains all the information needed to generate the expected output for the given input. Also note that we have set the passing threshold for each metric to 0.6, which means a test case will pass if and only if both metrics score higher or equal to 0.6.
PS. You should scroll up and revisit the chatbot QA diagram to see which part of the LLM system each metric evaluates.
Step 3: With our evaluation dataset and metrics ready, we can run our benchmark. We’re not going to implement a chatbot QA system, but lets assume we have a hypothetical function called run_chatbot_qa() that returns the generated response and the retrieved nodes used for response generation:
We can run the benchmark by first converting the goldens generated in step 1 to test cases that are ready for evaluation:
(Link to dataset documentation here)
Lastly, run your benchmark by executing your dataset on the two metrics you defined:
That wasn’t so difficult after all, right?
Text-SQL
Going full-circle, Text-SQL is a use case where an LLM system generates the relevant SQL query to answer a data analytical question. A data analytical question for example could be something like “How many users signed up last week”?
We’re going to reuse the same Text-SQL architecture diagram from the beginning of this article:
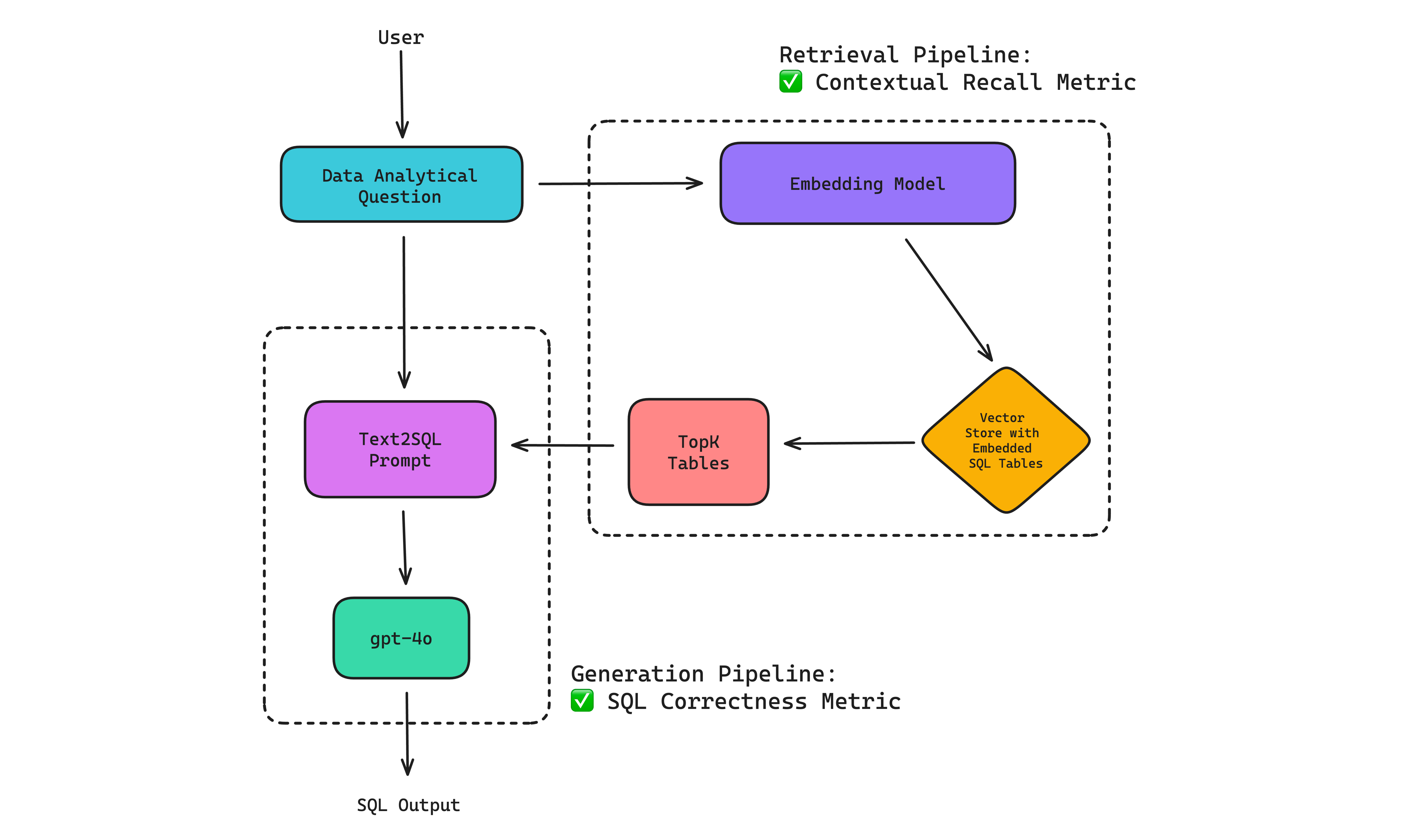
Step 1: For this synthetic data generation step, we’re going to generate synthetic goldens using data tables in a database schema.
(Link to synthesizer documentation here)
Step 2: We’ll be using the custom SQL correctness metric and contextual recall metric:
(Link to metrics documentation here)
Similar to metrics used in chatbot QA, the SQL correctness and contextual recall metric assess the generator and retrieval pipeline respectively.
Step 3: Let’s assume again we have another hypothetical function called run_text_2_sql() that returns the generated SQL query and the retrieved tabled used for SQL generation:
We can run the benchmark by first converting the goldens generated in step 1 to test cases that are ready for evaluation:
(Link to dataset documentation here)
Lastly, run your benchmark by executing your dataset on the two metrics you defined:
Conclusion
Congratulations on making this far! In this long article, we’ve learnt the difference between LLMs and LLM systems, and how we can evaluate them differently.
We also learnt what offline evaluations are, including the concept of benchmarking using custom datasets and metrics to regression test LLM systems, and how DeepEval helps throughout the entire evaluation lifecycle.. We also saw how important it is to improve benchmark datasets over time, and how real-time evaluations in production can help. Lastly, we went through two prominent LLM application use cases, such as chatbot QA and Text-SQL, and how to evaluate them.
Don’t forget to give ⭐ DeepEval a star on Github ⭐ if you found this article useful, and as always, till next time.
Do you want to brainstorm how to evaluate your LLM (application)? Ask us anything in our discord. I might give you an “aha!” moment, who knows?
Confident AI: The DeepEval LLM Evaluation Platform
The leading platform to evaluate and test LLM applications on the cloud, native to DeepEval.
Got Red? Safeguard LLM Systems Today with Confident AI
The leading platform to red-team LLM applications for your organization, powered by DeepTeam.



