After months of intense evaluation, red teaming, and iterating on hundreds of prompts for your LLM application, launch day is finally here. Yet, as the final countdown ticks away, those familiar doubts lingers: Have you truly covered all the bases? Could someone find an exploit? Is your model really ready for the real world? No seriously, is it really ready?
The truth is, no matter how thorough your preparation is, it’s impossible to test for every potential issue that could occur post-deployment. But here’s the good news — you’re not alone. With the right LLM monitoring, oversight, and observability tools, you can effectively manage and mitigate those risks, ensuring a smoother path ahead, which brings us to LLM observability.
By the end of this article, you'll be equipped with all the knowledge you need to empower your LLM application with observability. Let's begin.
What is LLM Observability?
LLM observability provides teams with powerful insights to keep LLMs on track, ensuring they perform accurately, stay aligned with business goals, and serve users effectively. With the right observability tools, you can monitor LLM behavior in real-time, A/B test different LLMs in production, easily detect performance shifts, and preemptively address issues before they impact the business or user experience. It’s a proactive approach to managing LLM applications that allows you to troubleshoot faster, maintain LLM reliability, and confidently scale your GenAI-driven initiatives.
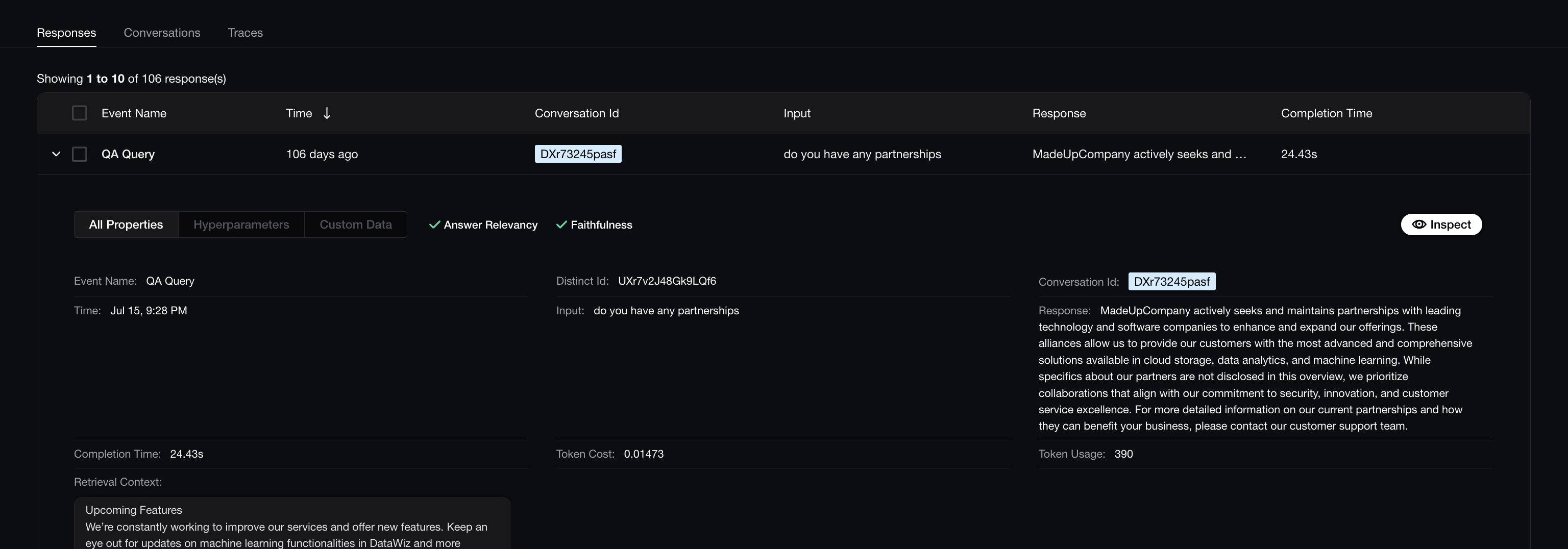
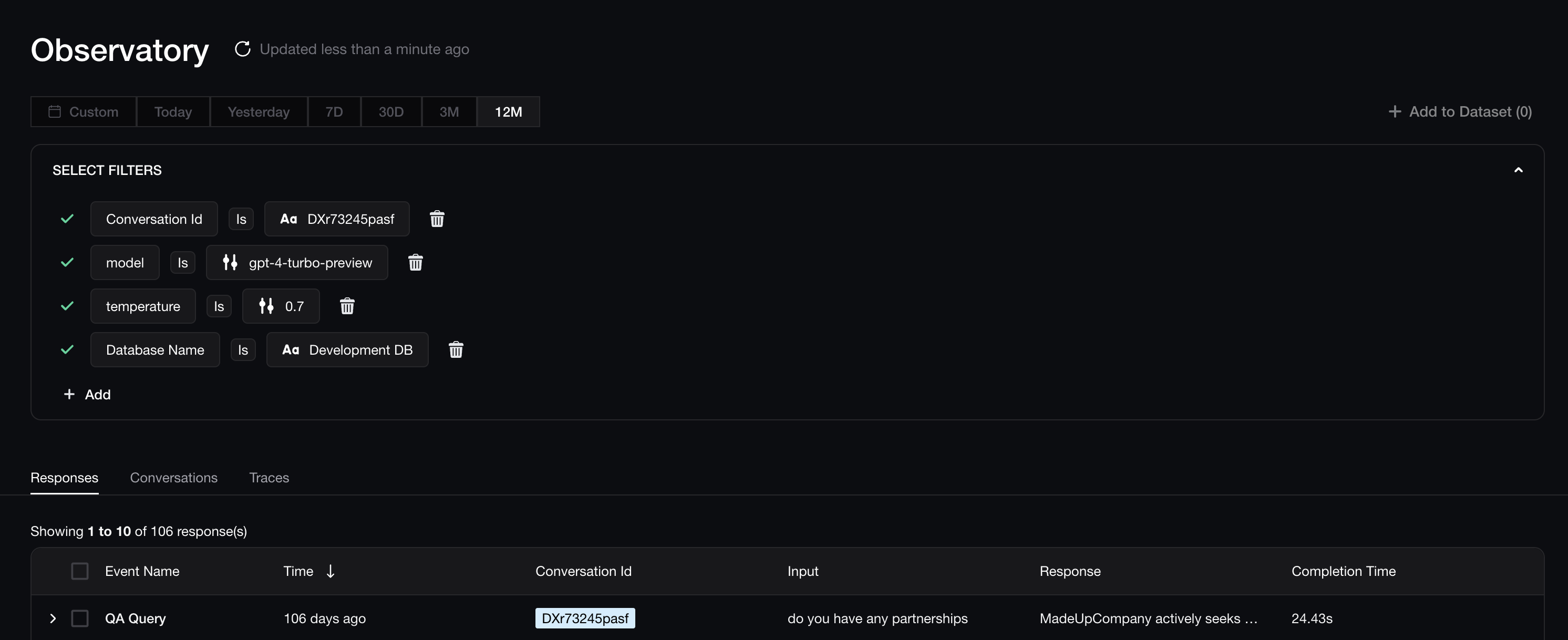
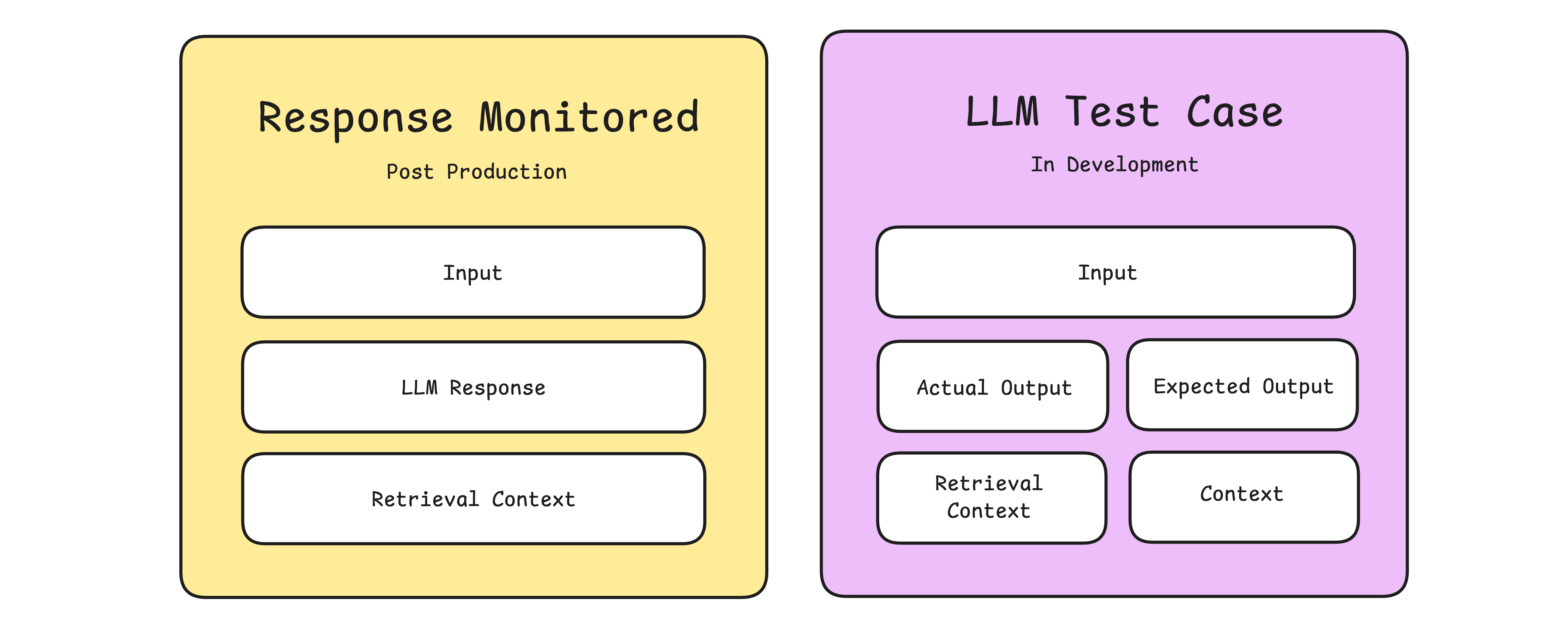
While LLM monitoring refers to tracking and evaluating various aspects of your LLM application in real-time, such as user inputs, model responses, latency, and cost, LLM observability on the other hand, provides deeper insights by giving full visibility into all the moving parts of the system, enabling engineers to debug issues and operate the application efficiently and safely. This concept of having full visibility into all components of your LLM pipeline, is often enabled by LLM tracing.
In a nutshell, here are the three key terminologies you ought to know:
LLM monitoring: This involves continuously tracking the performance of LLMs in production. Monitoring typically focuses on key metrics like response time, error rates, and usage patterns to ensure that the LLM behaves as expected and to identify any performance degradation or service issues that need attention.
LLM observability: This goes beyond monitoring to provide in-depth insights into how and why an LLM behaves the way it does. Observability tools collect and correlate logs, real-time evaluation metrics, and traces to understand the context of unexpected outputs or errors in real-time.
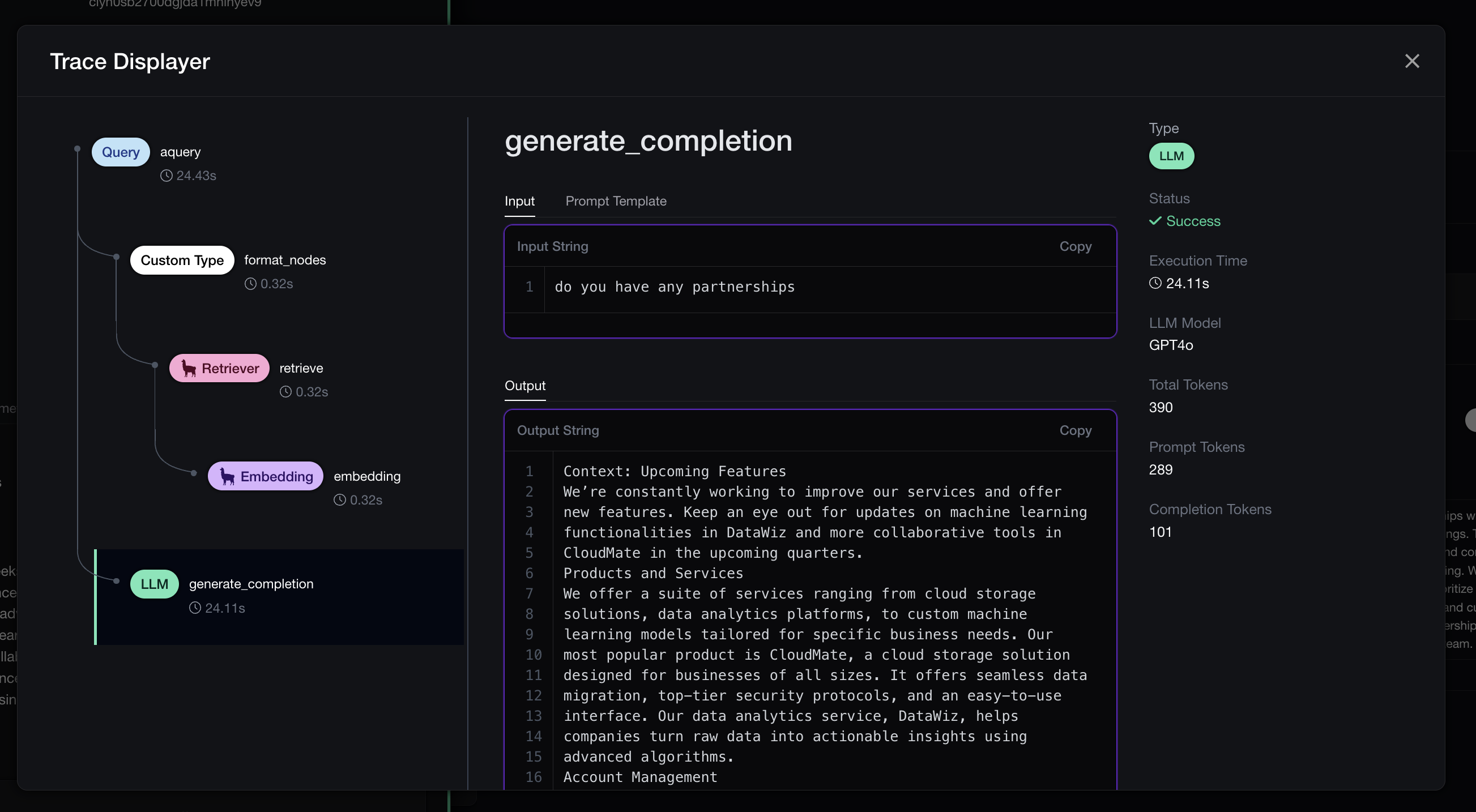
LLM tracing: Tracing captures the flow of requests and responses as they move through an LLM pipeline, providing a timeline of events from input to output. This granular view allows developers to track specific inputs, intermediate processing stages, and final outputs, making it easier to diagnose issues, optimize performance, and trace errors back to their root causes.
I'll be showing examples for each one of them in later sections but first, we'll discuss why LLM observability is imperative to productionizing LLM applications.
Why Is LLM Observability Necessary?
LLM observability helps many critical problems. Here are a few of them and why picking the right observability tool is so important.
LLM applications Needs Experimenting
No one gets it right the first time, which is why even when you've deployed to production you'll want to A/B test different LLMs to see which best fits your use case, use a different prompt template, or even use a whole different knowledge base as additional context to see how the responses change. This is why you definitely want a way to easily "replay" or recreate scenarios of which the responses were generated in.
LLM applications are Difficult to Debug
You've probably heard of root-cause analysis, and the unfortunate news is this is extremely difficult to do for LLM apps. LLM apps are made up of all sorts of moving parts — retrievers, APIs, embedders, chains, models, and more — and as these systems become more powerful, their complexity will only increase. Monitoring these components is key to understanding a range of issues: what’s slowing down your application, what might be causing hallucinations, and which parts may be unnecessary. With so much that could go wrong, gaining visibility into these areas is essential to keep your system efficient, effective, and bug-free.
Possibilities are Infinite with LLM responses
You can spend months curating the most comprehensive evaluation dataset to thoroughly test your LLM application, but let’s face it: real users will always surprise you with something unexpected. The range of possible queries is endless, making it impossible to cover everything with complete confidence. LLM observability enables you to automatically detect these unpredictable queries and address any issues they may cause.
LLMs can Drift in Performance
LLM applications are inherently non-deterministic, meaning you won’t always get the same output for the same input. Not only are they variable, but state-of-the-art models also evolve constantly, especially when working with third-party providers like OpenAI or Anthropic. This can lead to undesirable hallucinations and unexpected responses even after deployment. While testing LLMs during development is important, it’s simply not enough — continuous monitoring is essential as long as LLMs remain unpredictable and keep improving.
LLMs tend to Hallucinate
Hallucinations occur in LLM applications when they generate incorrect or misleading information, especially when faced with queries they cannot accurately address. Instead of indicating a lack of knowledge, these models often produce answers that sound confident but are fundamentally incorrect. This tendency raises concerns about the risk of spreading false information, which is particularly critical when LLMs are used in applications that require high factual accuracy.
Confident AI: The DeepEval LLM Evaluation Platform
The leading platform to evaluate and test LLM applications on the cloud, native to DeepEval.