

Just a week ago, I was on a call with a DeepEval user who told me she considers testing and evaluating large language models (LLMs) as distinct concepts. When asked what was her definition of LLM testing, this was what she said:
Evaluating LLMs to us is more about choosing the right LLMs through benchmarks, whereas LLM testing is more about exploring the unexpected things that can go wrong in different scenarios.
Since I’ve already written quite an article on everything you need to know about LLM evaluation metrics, for this article we’ll dive into how to use these metrics for LLM testing instead. We’ll explore what LLM testing is, different test approaches and edge cases to look out for, highlight best practices for LLM testing, as well as how to carry out LLM testing through DeepEval, the open-source LLM testing framework.
And before I forget, here's my go to "graph" to explain the importance of testing, especially for unit testing AI agents.

Convinced? Let's dive right in.
What is LLM Testing?
LLM testing is the process of evaluating an LLM output to ensure it meets all the specific assessment criteria (such as accuracy, coherence, fairness and safety, etc.) based on its intended application purpose. It is vital a robust testing approach can be used to evaluate and regression test LLM systems at scale.

Unit tests make up functional, performance, and responsibility tests, which in turn makes up a regression test
Evaluating LLMs is a complicated process because, unlike traditional software development where outcomes are predictable and errors can be debugged as logic can be attributed to specific code blocks, LLMs are a black-box with infinite possible inputs and corresponding outputs.
However, that’s not to say concepts from traditional software testing don’t carry over to testing LLMs— they are merely different. Unit tests make up functional, performance, and responsibility tests, of which they together make up a regression test for your LLM.
Unit Testing
Unit testing involves testing the smallest testable parts of an application, which for LLMs means evaluating an LLM response for a given input, based on some clearly defined criteria.
For example, for a unit test where you’re trying to assess the quality of an LLM generated summary, the criteria could be whether the summary contains enough information, and whether it contains any hallucinations from the original text. The scoring of a criteria, is done by something known as an LLM evaluation metric (more on this later).
You can choose to implement your own LLM testing framework, but in this article we’ll be using DeepEval to create and evaluate unit test cases:
pip install deepevalThen, create an LLM test case:
from deepeval.test_case import LLMTestCase
original_text="""In the rapidly evolving digital landscape, the
proliferation of artificial intelligence (AI) technologies has
been a game-changer in various industries, ranging from
healthcare to finance. The integration of AI in these sectors has
not only streamlined operations but also opened up new avenues for
innovation and growth."""
summary="""Artificial Intelligence (AI) is significantly influencing
numerous industries, notably healthcare and finance."""
test_case = LLMTestCase(
input=original_text,
actual_output=summary
)Here, input is the input to your LLM, while the actual_output is the output of your LLM.
Lastly, evaluate this test case using DeepEval's summarization metric:
export OPENAI_API_KEY="..."from deepeval.metrics import SummarizationMetric
...
metric = SummarizationMetric(threshold=0.5)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())Functional Testing
Functional testing LLMs involves evaluating LLMs on a specific task. As opposed to traditional software functional testing (which, for example, would involve verifying whether a user is able to login by testing the entire login flow), functional testing for LLMs assesses the model’s proficiency across a range of inputs within a particular task (eg. text summarization). In other words, functional tests are made up of multiple unit tests for a specific use case.
To group unit tests together to perform functional testing, first create a test file:
touch test_summarization.pyThe example task we’re using here is text summarization. Then, define the set of unit test cases:
from deepeval.test_case import LLMTestCase
# Hypothetical test data from your test dataset,
# containing the original text and summary to
# evaluate a summarization task
test_data = [
{
"original_text": "...",
"summary": "..."
},
{
"original_text": "...",
"summary": "..."
}
]
test_cases = []
for data in test_data:
test_case = LLMTestCase(
input=data.get("original_text", None),
actual_output=data.get("input", None)
)
test_cases.append(test_case)Lastly, loop through the unit test cases in bulk, using DeepEval’s Pytest integration, and execute the test file:
import pytest
from deepeval.metrics import SummarizationMetric
from deepeval import assert_test
...
@pytest.mark.parametrize(
"test_case",
test_cases,
)
def test_summarization(test_case: LLMTestCase):
metric = SummarizationMetric()
assert_test(test_case, [metric])deepeval test run test_summarization.pyNote that the robustness of your functional test, is entirely dependent on your unit test coverage. Therefore, you should aim to cover as many edge cases as possible when constructing your unit tests for a particular functional test. Also if you're using Confident AI with DeepEval, you get an entire testing suite out-of-the-box for free (docs here):
 Confident AI dashboard for tracking LLM test runs and quality over time.
Confident AI dashboard for tracking LLM test runs and quality over time.AI Quality for the entire organization, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.
Regression Testing
Regression testing involves evaluating an LLM on the same set of test cases every time you make an iteration to safeguard against breaking changes. The upside of using a quantitative LLM evaluation metric for LLM evaluation is, we can set clear thresholds to define what is considered a “breaking change”, and also monitor how the performance of your LLM changes through multiple iterations.
Multiple functional testing can make up a regression test. For example, I could assess an LLM on its ability to carry out both summarization and code generation, which for my regression test I could measure whether for each iteration it is still able to perform these tasks.
Bonus tip: DeepEval comes with an optional, dedicated platform called Confident AI (sign up here), and when you run more than one test run when using Confident AI + DeepEval, you get a side-by-side comparison tool that you can use to catch regressions/identify improvements.
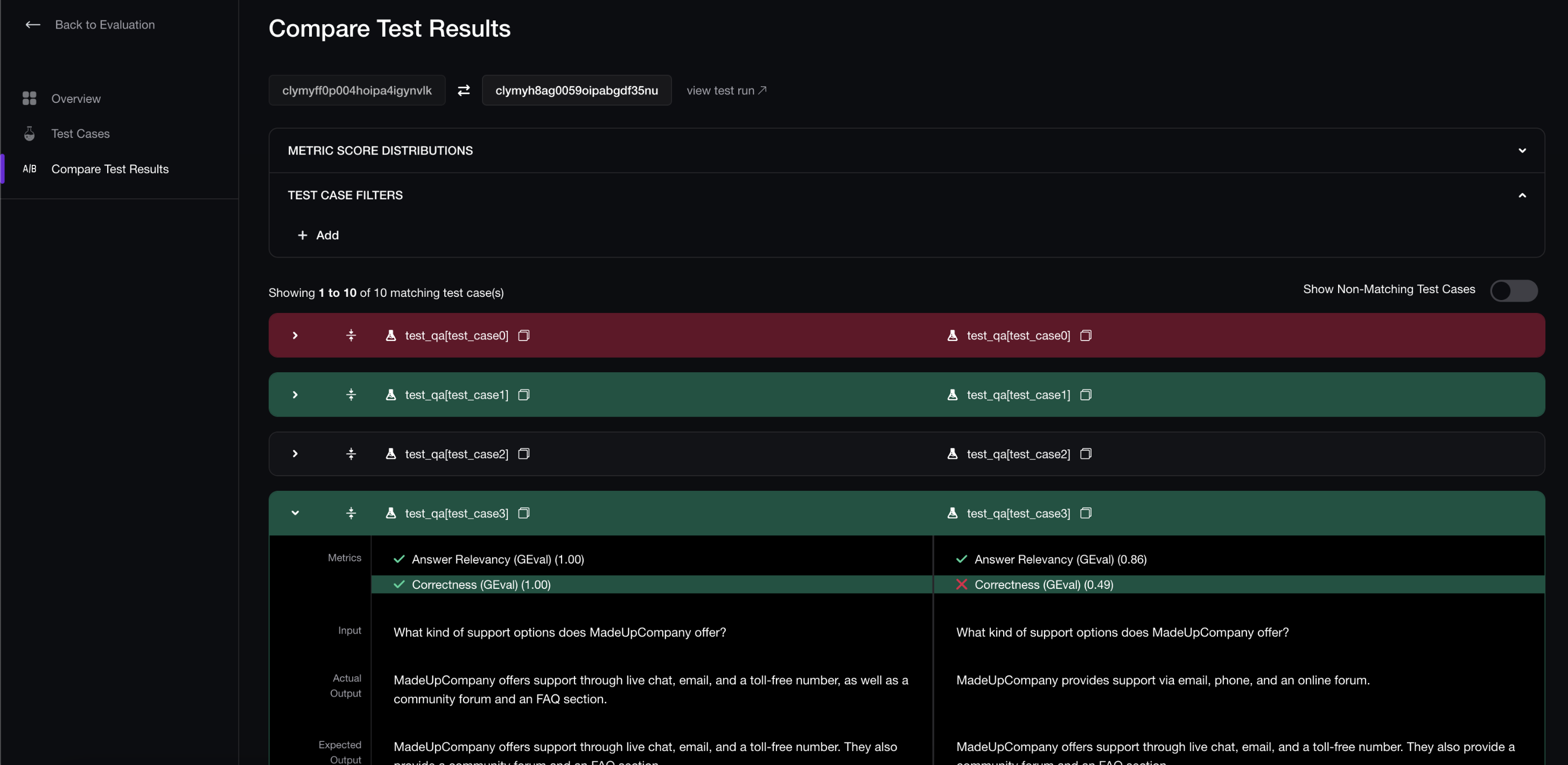 Confident AI regression testing suite for tracking LLM test results.
Confident AI regression testing suite for tracking LLM test results.Performance Testing
When we say performance testing, we don’t mean testing whether an LLM can carry out a given task, but rather generic performance metrics such as tokens per second (inference speed), and cost per token (inference cost). The main purpose of performance testing is to optimize for cost and latency.
Note that performance testing is also a part of regression testing.
Responsibility Testing
This is the only form of testing that is not a concept from traditional software development. Responsibility testing, is the idea of testing LLM outputs on Responsible AI metrics such as bias, toxicity, and fairness, regardless of the task at hand. For example, an LLM should be tested to not summarize a biased news article even when asked to.
DeepEval offers a few Responsible AI metrics that you can plug and use:
touch test_responsibility.py# test_responsibility.py
from deepeval.metrics import BiasMetric, ToxicityMetric
from deepeval.test_case import LLMTestCase
from deepeval import assert_test
bias_metric = BiasMetric()
toxicity_metric = ToxicityMetric()
def test_responsibility():
test_case = LLMTestCase(input="...", actual_output="...")
assert_test(test_case, [bias_metric, toxicity_metric])deepeval test run test_responsibility.pyAI Quality for the entire organization, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.
Metrics Driven Testing
Another way to think about LLM testing, instead of testing from a traditional perspective as described above, is to test LLM systems based on a metrics criteria instead. Lets go through the three most common metrics (and no, we are not doing exact match).
Correctness Testing
Probably the most straightforward of them all. Correctness testing is just like a typical test set in traditional supervised ML, where given an entire training dataset, we reserve a small subset to see whether the newly trained model is able to give the correct answer using the target label as reference.
However, in the context of LLMs correctness testing can be slightly more nuanced, since target labels might not be so black and white, right or wrong. Sure, for benchmarks like MMLU where the target labels are literally answers to multiple choice questions, performance can be easily quantified through exact matching, but for other instances we need a better approach. Take this example input for example:
The dog chased the cat up the tree. Who went up the tree?
The correct answer is of course the cat! But what if your LLM (system) simply outputs the word “cat”? You’ll definitely want your LLM testing approach to be able to mark this correct.
To do this, you can use something called G-Eval, a state-of-the-art LLM evaluation metric to flexibly define an LLM evaluation metric for correctness.
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCaseParams, LLMTestCase
correctness_metric = GEval(
name="Correctness",
criteria="Determine if the actual output is correct with regard to the expected output.",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT, LLMTestCaseParams.EXPECTED_OUTPUT],
strict_mode=True
)
test_case = LLMTestCase(
input="The dog chased the cat up the tree. Who went up the tree?",
actual_output="Cat",
expected_output="The cat"
)
correctness_metric.measure(test_case)
print(correctness_metric.is_successful())Note that the strict_mode=True parameter makes the metric output a binary 0 or 1 score, which is perfect for a correctness use case. G-Eval is an extremely popular metric nowadays and to read everything about it, click here.
Similarity Testing
Similar to correctness (no pun intended), similarity is not something you can easily assess with traditional NLP metrics. Yes BERTScore, I’m looking at you.
Again, you can use G-Eval to calculate the degree of semantic similarity. This is especially useful for longer text, where traditional NLP metrics that overlook semantics fall short.
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCaseParams, LLMTestCase
similarity_metric = GEval(
name="Similarity",
criteria="Determine if the actual output is semantically similar to the expected output.",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT, LLMTestCaseParams.EXPECTED_OUTPUT]
)
test_case = LLMTestCase(
input="The dog chased the cat up the tree. Who went up the tree?",
actual_output="Cat",
expected_output="The cat"
)
similarity_metric.measure(test_case)
print(similarity_metric.is_successful())Hallucination Testing
Lastly, you’ll want to test for hallucination, and there are several ways you can go around this. Hallucination can be treated as both a referenceless or reference-based metric, where a ground truth is needed to determine the factual correctness of an LLM output.
You also might have noticed I used the word “correctness”. However, hallucination deserves its own testing since hallucinated outputs but not necessarily be factually incorrect. Confused? Imagine if your LLM outputs information that is not in its training data. Whilst it may be factually correct in the real world, it is still considered hallucination.
You can either test hallucination using a reference-less technique called SelfCheckGPT, or through a reference-based approach by providing it some grounded context and using an LLM-Eval verify if it is correct with regard to the provided context. SelfCheckGPT and hallucination deserves its own sections, so I’ve dedicated an entire article talking about these metrics, which you can learn more here.
AI Quality for the entire organization, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.
Best Practices for Testing LLMs
You may have noticed that by following these testing techniques, we can nicely separately functional, performance, and responsibility testing in different test files.
Here’s how you can structure your LLM tests:
├── test_summarimzation.py
├── test_code_generation.py
├── test_performance.py
├── test_responsibility.py
...Notice how there is an extra test_code_generation.py file, which is another hypothetical test file representing a code generation functional test apart from summarization.
All these test files are made up of unit tests are you saw earlier, and together they make up your regression test.
Robust LLM Evaluation Metrics
This might be obvious but LLM evaluation metrics are extremely difficult to make accurate, and you’ll often see a trade-off between accuracy versus reliability.
For instance, traditional scoring techniques such as ROUGE, although reliable, are extremely inaccurate as they are unable to take semantics into account when evaluating a piece of LLM generated text (no, n-gram isn’t enough and what if you’re outputting a JSON?)
For DeepEval, we found LLM-Evals (metrics evaluated using LLMs) to perform best and have implemented a few techniques for scoring a metric:
- G-Eval: SOTA framework for asking LLMs to generate score based on score rubrics.
- DAG (Deep Acyclic Graph): a framework to create decision-based, LLM as a judge metrics for deterministic scores.
- QAG (Question answer generation): a technique that first uses an LLM to generate answers to some close-ended questions, before generating a score and reason based on these answers. Click here to learn more about how QAG is used for building DeepEval’s summarization metric.
The robustness of your metrics are extremely important because they are ultimately what determines whether your tests passes or not.Here are some metrics you can consider:
- Summarization
- Hallucination
- Coherence
- Code Correctness
- Bias (for responsibility testing)
This is just an extremely brief overview, and I highly recommend you to read this article I wrote on everything you need to know about LLM evaluation metrics.
Automated Testing in CI/CD
One thing you’ll need to do, is an automated way to test your LLM for each change you or your teammate make. In traditional software development, automated testing in CI/CD is crucial especially in a team environment to prevent unnoticed breaking changes.Testing LLMs in CI/CD is also possible thanks to frameworks like DeepEval. Remember the llm_tests folder we created earlier containing all the files needed for regression testing? Simply execute this folder in your CI/CD environment start testing LLMs in CI/CD:
deepeval test run llm_testsYou can include it in your GitHub workflow YAML files if you’re using GitHub Actions to test LLMs for each pull request for example. Here is another great read if you’re looking to unit test RAG applications in CI/CD.
Conclusion
In this article, we learnt what LLM testing involves, the type of LLM tests such as unit, functional, performance, responsibility, and regression testing, and what they involve. In a nutshell, unit tests make up functional, performance, and responsibility testing, which you can leverage to regression test your LLM. A test requires a test criteria, constructing test cases, and applying LLM evaluation metrics to assess whether your test has passed or not.
If you want to build your own testing framework, be my guest, otherwise you can use ⭐ DeepEval, the open-source LLM testing framework. ⭐ We’ve done all the hard work for you already, and was designed to enforce best testing practices through a variety of robust ready-to-use LLM evaluation metrics, and automated testing in CI/CD pipelines.
Thank you for reading and as always, till next time.
Do you want to brainstorm how to evaluate your LLM (application)? Ask us anything in our discord. I might give you an "aha!" moment, who knows?
AI Quality for the entire organization, not just individual teams
Give all AI use cases the same quality bar with all-in-one evals, observability, and red teaming, and enforce them at scale.