Picture LLMs ranging from 7 billion to over 100 billion parameters, each more powerful than the last. Among them are the giants: Mistral 7 billion, Mixtral 8x7 billion, Llama 70 billion, and the colossal Falcon 180 billion. Yet, there also exist models like Phi1, Phi1.5, and Falcon 1B, striving for similar prowess with a leaner framework of 1 to 4 billion parameters. Each model, big or small, shares a common goal: to master the art of language, excelling in tasks like summarization, question-answering, and named entity recognition.
But across all of these cases, Large Language Models (LLMs) universally share some very flawed behaviors:
Some prompts cause LLMs to produce gibberish outputs, known as 'jailbreaking prompts'.
LLMs are not always factually correct, a phenomenon also known as 'hallucination'.
LLMs can exhibit unexpected behaviors that are unsafe for consumers to utilize.
It is evident that merely training LLMs is not sufficient. Thus, the question arises: How can we confidently assert that LLM 'A' (with 'n' number of parameters) is superior to LLM 'B' (with 'm' parameters)? Or is LLM 'A' more reliable than LLM 'B' based on quantifiable, reasonable observations?
There needs a standard to benchmark LLMs, ensuring they are ethically reliable and factually performant. Although a lot of research has been done on benchmarking (eg. MMLU, HellaSwag, BBH, etc.), merely researching is also not enough for robust, customized benchmarking for production use cases.
This article provides a bird's-eye view of current research on LLM evaluation, along with some outstanding open-source implementations in this area. In this blog you will learn:
Scenarios, Tasks, Benchmark Dataset, and LLM Evaluation Metrics
Current research on benchmarking LLM and the current problems with them
Best practices for LLM Benchmarking/Evaluation
Using DeepEval to enforce evaluation best practices
Scenario, Task, Benchmark Dataset, and Metric
“Scenario”, “Task”, “Benchmark Dataset” and “Metric” are some frequently used terms in the evaluation space, so it is extremely important to understand what they mean before proceeding.
Scenario
A scenario is a broad set of contexts/settings or a condition under which LLM’s performance is assessed or tested. For example:
Question Answering
Reasoning
Machine Translation
Text Generation and Natural Language Processing.
Several popular benchmarks already exist in the field of LLMs, including MMLU, HellaSwag, and BIG-Bench Hard for example.
Task
As simple as it sounds, a task can be thought of as a more granular form of a scenario. It is more specific on what basis the LLM is evaluated. A task can be a composition (or a group) of a lot of sub-tasks.
For example, Arithmetic can be considered as a task. Where it clearly mentions it evaluates LLMs on arithmetic questions. Under this, there can be a lot of sub-tasks like Arithmetic Level 1, Level 2, etc. In this example, all the arithmetic sub-tasks (from level 1 to 5) make up the Arithmetic task.
Similarly, we can have Multiple Choice as a task. Under this, we can have Multiple choice on history, algebra, etc., as all the subtasks. In fact, MMLU is based entirely on multiple choices.
Metric
A metric can be defined as a qualitative measure used to evaluate the performance of a Language Model on certain tasks/scenarios. A metric can be either a simple:
Deterministic statistical/mathematical function (eg., Accuracy)
Or a score produced by a Neural Network or an ML model. (eg., BERT Score)
Or score generated by the help of LLMs itself. (eg., G-Eval)
In fact, you should read this full article if you want to learn everything about LLM evaluation metrics. For now, here is a brief overview:
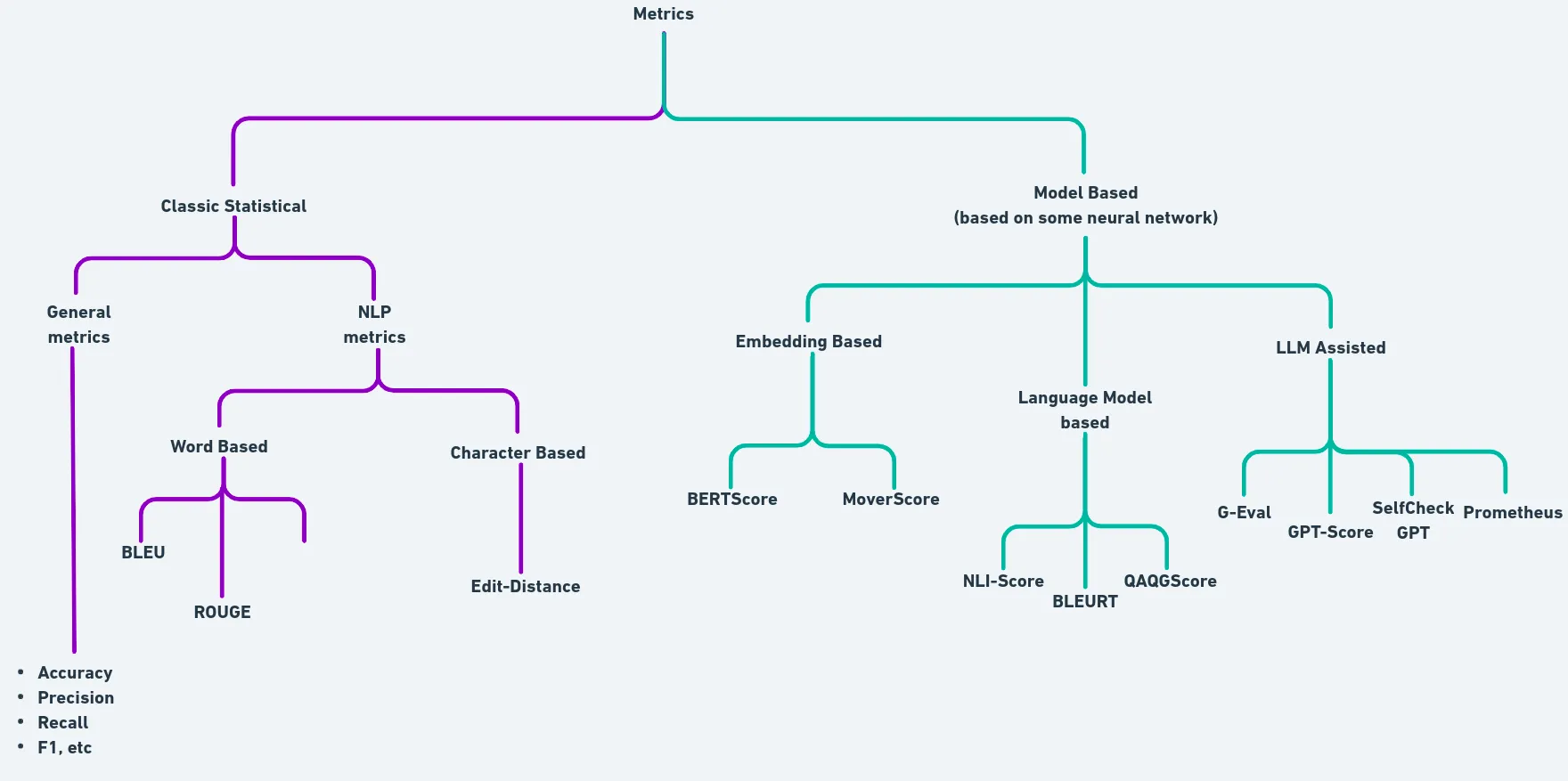
The above figures try to simplify the taxonomy of the classification of different types of metrics used in LLM evaluation. A metric can also be a composition of different atomic/granular metrics. A very simple example is the F1-score which is the harmonic mean of precision and recall.
Similarly in NLP, the BLEU (Bilingual Evaluation Understudy) score is a composition of precision, brevity penalty, and N-gram matching. If you wish, you can also club different metrics to come up with a new metric.
Benchmark Dataset
A benchmark dataset is a standardized collection of test sets that is used to evaluate LLMs on a given task or scenario. Here are some examples:
In most of the cases presented in later sections, you will see that a scenario can often consist of a lot of benchmark datasets. A task might consist of a lot of sub-tasks and each sub-task can consist of a bunch of datasets. But, it can also simply be a task that contain some benchmark dataset under it.
Current Research Frameworks for Benchmarking LLMs

In this section we are going to look into various benchmarking frameworks, and what they offer. Please note: right now there is no standardization in naming conventions. It might sound very confusing when understanding this for the first time, so bear with me.
Language Model Evaluation Harness (by EleutherAI)
Language Model Evaluation Harness provides a unified framework to benchmark LLMs on a large number of evaluation tasks. I intentionally highlighted the word task, because, there is NO such concept of scenarios in Harness (I will use Harness instead of LM Evaluation Harness).
Under Harness, we can see many tasks, which contains different subtasks. Each task or set of subtasks, evaluates an LLM on different areas, like generative capabilities, reasoning in various areas, etc.
Each subtask under a task (or even sometimes the task itself) has a benchmark dataset and the tasks are generally associated with some prominent research done on evaluation. Harness puts a great effort into unifying and structuring all those datasets, configs, and evaluation strategies (like the metrics associated with evaluating the benchmark datasets), all in one place.
Not only that, Harness also supports different kinds of LLM backends (for example: VLLM, GGUF, etc). It enables huge customizability on changing prompts and experimenting with them.
This is a small example of how you can easily evaluate the Mistral model on the HellaSwag task (a task to judge the common sense capability of an LLM).
lm_eval --model hf \
--model_args pretrained=mistralai/Mistral-7B-v0.1 \
--tasks hellaswag \
--device cuda:0 \
--batch_size 8Inspired by LM Evaluation Harness, there is another framework called BigCode Evaluation Harness by the BigCode project that tries to provide similar API and CLI methods to evaluate LLMs specifically for code generation tasks. Since evaluation for code generation is a very specific topic, we can discuss that in the next blog, so stay tuned!

Confident AI: The DeepEval LLM Evaluation Platform
The leading platform to evaluate and test LLM applications on the cloud, native to DeepEval.